杭州做搜索引擎网站的公司公共资源交易中心职责

大家都知道我们可以使用C语言写一段程序来控制硬件工作,但你知道其工作原理吗?
网友北极
C语言在实际运行中,都是以汇编指令的方式运行的,由编译器把C语言编译成汇编指令,CPU直接执行汇编指令。
所以这个问题就变成,汇编指令是如何操作硬件的?
如果把硬件平台限制在x86环境下,那么汇编指令操作硬件基本上只有两种方式:
方式一:
通过向内存空间写数据。硬件会把硬件上的各种寄存器(外行可以理解为访问硬件的接口或者操作硬件的工具)映射到某一块内存地址空间上,之后只要用汇编指令,甚至C语言去读写这一段内存地址空间(并非真正操作物理内存),就可以达到操作硬件的目的了。
如果题主还有WindowsXP环境(虚拟机也可以),就可以用汇编指令直接操作显存:
MOV AX,B800
MOV ES,AX
XOR DI,DI
MOV CX,0800
MOV AX,5555
REPZ STOSB
硬件的各种寄存器会被映射到某一块物理内存中,这种方式称为MMIO,在Windows的设备管理器里,右键点设备,看属性-》资源里,不少硬件设备都有“内存范围”的参数,这里的内存范围就表示这个硬件的资源可以通过访问这一段内存来控制它。
具体如下图:
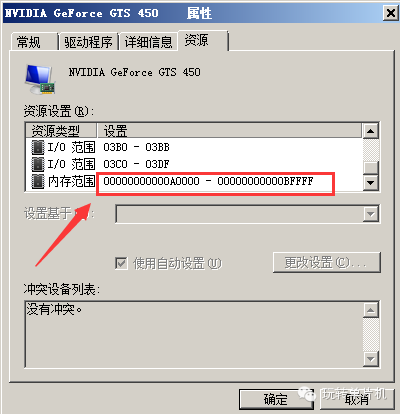
方式二:
x86汇编中,还有两个特殊的指令是IN和OUT,这是x86平台独有的,上面图里的I/O范围,就是用IN/OUT这两个指令来访问和控制的。
以上两种访问硬件的方式,第一种是可以用C语言实现的,上面一段汇编,本质上类似于C语言代码:
char ptr = 0xB8000;
int i;
for (i = 0; i 《0x800; i++)
{ptr + i = 0x55;
}
第二种IN/OUT方式没有直接的C语言语法对应,需要自己封装汇编。
那么为什么平时很难用C语言操作硬件呢?这是因为平时写的代码大多数都在保护模式下,保护模式下,直接访问物理地址会受到限制,C语言操作的地址都是虚地址。
对于Windows来说,要访问物理地址,需要工作在内核模式,也就是的写驱动才行。
而在显存方面,首先,题主要先明白物理地址和虚拟地址的概念。
原来的8086cpu设计的时候,地址空间有一块区域(640K-1M)之间,有一块作为显存使用
这里你说的预留的地址,是指物理地址,这一段地址的准确范围是000A0000-000BFFFF,不管是32位还是64位CPU,这一段物理内存地址一直都保留给显存使用,不区分32位还是64位,也不区分保护模式还是实模式。
以下是我电脑上的截图(系统环境为Win7 64位,CPU是i7 4770K):
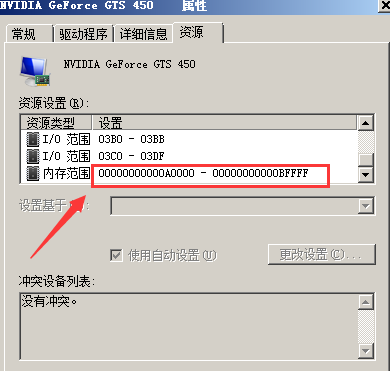
可见这一段内存至今仍然是留给显卡使用的。
那么现在为什么不能直接用这段内存了?
因为现在的软件都运行在保护模式下,访问的地址都是虚拟地址,而并非物理地址,包括你使用cmd命令打开的环境,都是虚拟地址,虽然32位XP里能用debug命令向000B8000上写数据并能显示在cmd的界面里,但本质上,这都是虚拟出来的。
如果要想用这段显存怎么办?
自己写一个简易的操作系统,不启动显卡的各种图形加速功能,CPU进入保护模式后在GDT里映射一个4G的数据段,与物理地址一致,那么向000B8000上写数据,就会像过去DOS一样显示在屏幕上,所以保护模式下也可以访问这一段内存。所以,保护模式下,也可以用它。
显卡那么多显存是怎么映射的?
再看截图:
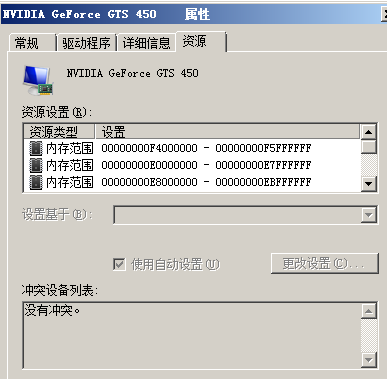
有很多内存地址被映射给显存了,就是通过这种映射关系,把一些物理地址留给显存,使得CPU能像访问内存一样访问显存资源。
当然,实际情况是,2G显存未必完全映射,而是只映射一部分地址,显卡有一些开放的寄存器能够控制哪部分显存映射过来,这样就能使得CPU在使用比较少的物理地址范围的情况下,访问全部的显存。
还有一个很有意思的事情:在虚拟机里,找到映射的高地址部分的第一块内存区域,写一个能直接访问物理地址的程序(比如一个驱动),去读这一块内存,然后写到文件里,再用屏幕截图,也写到文件里,会发现截图的内容和显存里读出来的内容基本上是一样的。
网友awayisblue
要回答你的问题,我们需要要知道:
硬件是一种什么样的存在
什么是驱动。
C语言怎么操作硬件
我就不严格去定义这些概念了,我就以一个例子来通俗地讲解一下吧。
首先讲硬件:先介绍一款单片机芯片STM8。

这款芯片里面有cpu, 内存,寄存器(先不要觉得看到新名词压力大,继续往下看)等等,相当于我们的电脑了,但还要外接其它硬件。
这里你需要知道的概念是:
芯片的引脚跟寄存器是相对应的,寄存器是8位的内存单元(对,存在于内存上面),当你往这个内存单元里面写入数据时,芯片的引脚的电压会发生变化,比如说我写入的是01100001,则芯片上与之对应的8个引脚的电压状态(分为高电平与低电平两种)会输出:低高高低低低低高。
cpu可以执行代码指令,指令可以操作内存。
结论:所以从上面两点可以我们可以知道,cpu可以执行指令,使芯片的引脚电平(电压)发生变化。
接下来我们再来看另一个硬件,液晶显示器LCD1602(对,我就是这么迷你):
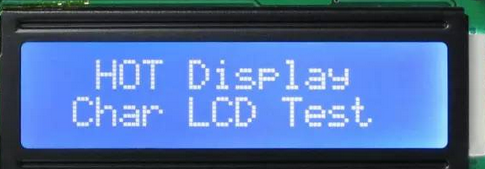
关于这款显示器,我们需要知道的是:
它是有引脚的,这些引脚可以跟到前面介绍的那款单片机芯片的引脚相连。
该显示器有自带的内存,用于存储要显示的字符,显示器从该内存里面读取字符来来显示。单片机芯片与该显示器相连后,可以通过引脚往该显示器的内存里写数据(通过多个引脚电平的高低不同来代表不同的数据,比如说:低高高低低低低高 代表01100001,这个数据写在显示器的内存里面,被显示器所显示,当然,会根据ASCII来显示数字对应的字符,01100001对应的字符是‘a’),除了接收数据的引脚外,还有控制显示器的引脚(这个我们会在驱动那里介绍,继续往下看)。
结论:单片机芯片与显示器相连,可以通过引脚输出的电平来控制显示器的字符显示。
那么,综合上面,也就是说,单片机芯片cpu可以通过执行指令来控制显示器的字符显示。
而这里,题主所说的硬件,指的就是这个显示器了。
接下来讲驱动:
那么,什么是驱动呢?驱动无非就是硬件跟软件的中间层,但我们不纠结这种关系,直接来看一下,对于我们这个例子,驱动指的是什么。首先我们要知道:
显示器支持很多种操作,比如说清除显示,光标移动,读取数据,写数据等等。
这些操作数据引脚和控制引脚来实现。
引脚可以通过单片机芯片来控制。
结论:我们可以通过在单片机芯片里面写显示器的“驱动”程序来屏蔽掉硬件(显示器硬件)层。
于是这里驱动程序,指的是显示器所支持操作的程序表示。比如说清除显示,我们可以编写一个clear()函数,光标移动,我们编写一个move_cursor()函数,读取数据和写数据分别为read()和write(),然后分别实现就可以了(通过向寄存器里写数据的形式,进而控制引脚的电平变化,再而控制显示器,这个过程前面已有介绍)。这些函数就是驱动程序了。为什么上面说驱动程序可以屏蔽掉硬件呢?因为程序员可以使用前面的驱动程序来直接操作显示器(硬件),而不用知道太多关于硬件的事情,而一般的驱动程序也可以由厂家来提供。
再说明一点:一般这些驱动程序可以用汇编写(出于运行效率的考虑),也可以用C语言来编写的,比如说我上面的例子,就可以直接用C语言来编写。当然C语言内联汇编的形式也可以。
最后讲C语言怎么操作硬件:
相信到这里,C语言是怎么操作硬件的已经比较明白了。
这里总结一下:C语言由CPU运行(实际上是先编译成机器码存在芯片里面然后执行),可以去操作内存。
内存里有一段是跟寄存器相对应的,而寄存器是跟芯片的引脚相对应的,于是操作该段内存就能控制芯片引脚的电压变化。
硬件(比如说显示器)有引脚(或者说排线,这些也是一样的东西),这些引脚跟芯片的引脚相连可以接受芯片的控制。
可以把对某个硬件的操作做成一系列操作函数,这些操作函数就是驱动程序了。
于是我们的C语言只要去调用这个驱动程序就可以直接操作硬件了。(当然驱动程序也可以由C语言来编写,所以C语言操作硬件并不一定要经过驱动程序)。
网友Chow Anod
北极已经说的很到位了。我补充一些知识点:
1 语言层面上,C能直接操作的“硬件”只有内存地址。虽然C支持register关键字,但是不能指定某个特定的寄存器,所以只有内存地址。而C中操作内存地址的方式就是指针。例如:
char p = 。..;p = 。..;
2 根据1反推,可以明白如果要开放给C来操作某个硬件,最直接的方案就是设计硬件的时候预先分配好一些固定的地址的用途,然后实际项目中往这些固定地址写入合法的数据。这样就可以通过类似
uint32_t p = SCREEN_ADDR;p = RGBA(0xff,0xff,0xff,0xff);
这样的代码来实现对硬件的操作了。
3 那这个地址怎么拿到呢?什么样的数据才是合法的呢?要解答这些问题,就需要查阅具体设备的spec了。例如这个一眼看过去就能的明白的例子(一眼没看明白请反复阅读以完全理解上面第二点内容):
PS:x86架构的代码不能这么写,原因见北极的回答。
网友北极
我们是用电脑的键盘来输入的指令,每一个指令都对应一个ASCII码,而这里的ASCII码就是有序的电压的高低(或电流的有无,下面只提电压的高低),即我们输入的是电压的高低,你所看到代码是这些电压的高低控制显示器所显示的图像,其实电脑也不知道它是什么,只知道这样显示。
结论:代码其实就是存储在存储器(内存、硬盘或者闪存等等)中有序的电压的高低。
再说编译:
编译是一个有序的电压的高低向另一种有序的电压高低的一种转换过程,下面以52单片机为例,我们编译是从表示ASCII码的那种有序电压高低转换为52单片机能够识别的另一种规定好的有序电压高低,即表示HEX文件的电压高低。
结论:编译出的结果还是电脑中存储的有序电压高低。
到单片机烧录:
接下俩就是烧录,理解了上面两点就很容易理解下面的内容,烧录就是电脑中的有序电压高低通过数据线传输到单片机中的ROM中。
接下来ROM就可以释放其中的电压来控制外围的电路。
总结:从代码的编辑到最后对电路的控制都是电压在起作用,只是为了方面我们而给我们展现的形式不一样而已,而其本质都是电压,这样也就不存在转换。
理解这句话:世界上没有软件,软件只是对硬件的一种反映,就像意识是对世界的一种反映是一样的!
相信这样就很容易理解了。
看到有人赞同了我的观点,很开心,针对题目我再补充一点:
只要你提到0/1,提到软件,这个问题就没法理解。..因为软件【包括0/1】和硬件始终存在一道无法跨越的鸿沟;
你说你在单片机中写0,请问你是如何写0的?在键盘上敲个0?实际还是电平【和我们理解的数字没关系】,那个0只是你在电脑显示器上电平的呈现形式,那个所谓的0【实质是电平】可以传输到单片机中的ROM中,电平控制电平没什么疑问吧,这样就输出低电平了。
-END-
推荐阅读
【01】C语言指针用得好犹如神助!这些使用技巧值得收藏【02】C语言中,全局变量滥用的后果竟如此严重?【03】太巧妙了!适合 MCU 用的 C语言 快速互转 HEX (16进制) 方法!【04】值得收藏的 C语言 指针讲解文章【05】嵌入式必会!C语言 最常用的贪心算法就这么被攻略了免责声明:整理文章为传播相关技术,版权归原作者所有,如有侵权,请联系删除