网站模板目录扫描如何制作专业简历
不久前,微软决定在2022年6月15日彻底放弃IE浏览器,全线改用Microsoft Edge。微软官方表示,"我们宣布,Windows 10上的Internet Explorer的未来在Microsoft Edge中,Internet Explorer 11桌面应用程序将于2022年6月15日退役并停止对某些版本的Windows 10的支持。"

诚然,Windows 10的长期服务渠道(LTSC)明年仍将包括IE浏览器的支持,但所有消费者版本的后续服务将不再提供。微软没有明确说明退役的方式,猜测IE浏览器在2022年6月后会步Flash后尘。
必须说明的是,现在国内很多单位对IE浏览器有较强依赖性,比如一些银行的网银,就必须基于IE浏览器,还比如一些机关单位的系统也必须基于IE浏览器。

在Flash停止服务后,某单位就发生因新购置并安装最新Flash版本的电脑无法通过浏览器访问业务系统的情况,可以说,一个小小的“插件停服”就导致相关系统有“瘫痪”风险。虽然最终解决了问题,但是问题背后的安全隐患让人担忧。
在党政机关和八大行业国企广泛应用Windows系统,运行IE和Flash的情况下,微软先后对Windows7、IE和Flash停服,会对用户单位造成很大风险。此前,由于党政办公系统中就广泛的使用Flash进行资源开发(政府部门官网、业务办理系统中的表单控件等),大家在使用的过程中就经常受到Flash的各种困扰。Flash停止服务,浏览器厂商不再为Flash插件提供运行环境,基于Flash资源的网站/业务系统无法再被Windows的IE浏览器加载,直接影响到了国内政企用户业务的正常运行。往小了说是用户体验差,往大了说是信息系统不可控,系统的正常运行与否完全掌握在别人的手中。如今,微软淘汰IE浏览器,国内一些机关单位和国有企业将面临更加麻烦的情况。
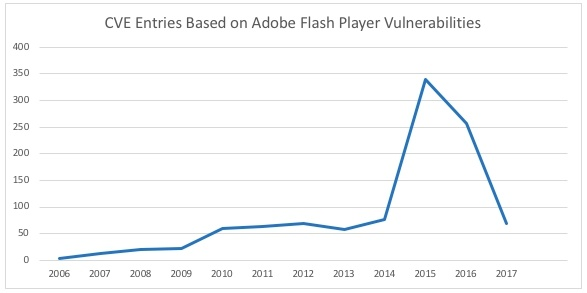
正如Flash被安全厂商诟病已久(在CVE平台内记录的Adobe Flash漏洞多达1000多条,而且大多都较严重。有着跨平台特性的Flash,也成为当前最好用的病毒开发工具,甚至一些漏洞被利用在带有政治目的的攻击中),“寿命”高达25年的IE浏览器同样弊病丛生,在微软停服后,IE浏览器的安全风险将会被进一步放大。
正如Flash退出历史舞台后,国内一些工商把HTML5作为最为合适的替代者,越来越多的网站开始向HTML5迁移和升级。统信甚至还基于自研技术路线的整体替代Flash的解决方案ReFla,协助业务系统开发厂商、合作伙伴与用户单位解决Flash停服的影响,保证各项业务的顺利运行。
希望国内软件公司能够再接再厉,拿出IE浏览器的替代者,并在党政机关和国企率先应用,彻底解决相关单位重要业务被IE浏览器“绑架”的问题。