网站设计公司南京如何免费建一个wordpress
背景
随着数字化时代的来临,新媒体营销成为企业推广和品牌建设的关键手段。为了培养高职学生在新媒体领域的实际操作能力,建立一套全面、系统的实训室方案至关重要。
目标
搭建高职新媒体营销实训室,旨在培养学生的实际操作能力,使其具备在现代企业中从事新媒体营销工作的能力。
实训室设备与工具
电脑工作站: 配备高性能电脑,确保学生能够顺畅地进行多媒体编辑、图形设计和数据分析等操作。
多屏显示系统: 提供多屏幕显示,以模拟真实工作环境,增加学生的多任务处理能力。
高清摄像设备: 用于拍摄和编辑视频内容,培养学生视频制作和编辑的技能。
音频设备: 包括专业麦克风、音响系统,用于学生音频内容的录制和编辑。
新媒体管理软件: 安装并提供新媒体管理工具,如社交媒体管理平台、内容编辑软件等,以便学生熟练操作。
新媒体营销实训平台:新媒体营销实训平台是为高职学生提供全面、实用的新媒体营销培训的在线学习平台。通过该平台,学生将获得理论知识与实际操作相结合的培训,提高在数字营销领域的就业竞争力。
实时数据分析工具: 集成实时数据分析工具,帮助学生理解和应用数据分析在营销活动中的作用。
新媒体营销实训平台介绍
《新媒体营销实训平台》是一款旨在提高文章发布效率的全面新媒体内容管理工具。该平台为用户提供了一套简便易用的解决方案,使文章编辑、排版和发布变得轻松而高效。以下是平台的主要功能和优势:
主要功能和优势:
简单易用: 平台设计简洁,操作流程明确,用户无需专业技术背景即可快速上手。
多平台支持: 一键发布功能使用户能够同时在多个主流新媒体和博客平台上发布文章,如百家号、公众号、知乎、CSDN等,实现一站式发布。
强大编辑器: 支持Word导入,自动排版,使文章呈现更专业、美观的效果,提升内容质量。
提高效率: 一键发布功能避免了繁琐的重复操作,使用户能够更专注于内容创作。
账号管理: 用户可灵活管理和组织多个平台账号,实时检测账号状态,确保账号的正常运行。
文章管理: 提供编辑、删除和查看已发布文章的发布状态等功能,方便用户对内容的管理和维护。
运行环境:
平台采用高效的B/S架构和先进的SpringCloud等技术,实现了无限制用户同时访问的能力。
通过插件的形式实现与各平台的API对接,使用Chrome浏览器可获得最佳的用户体验。
功能介绍:
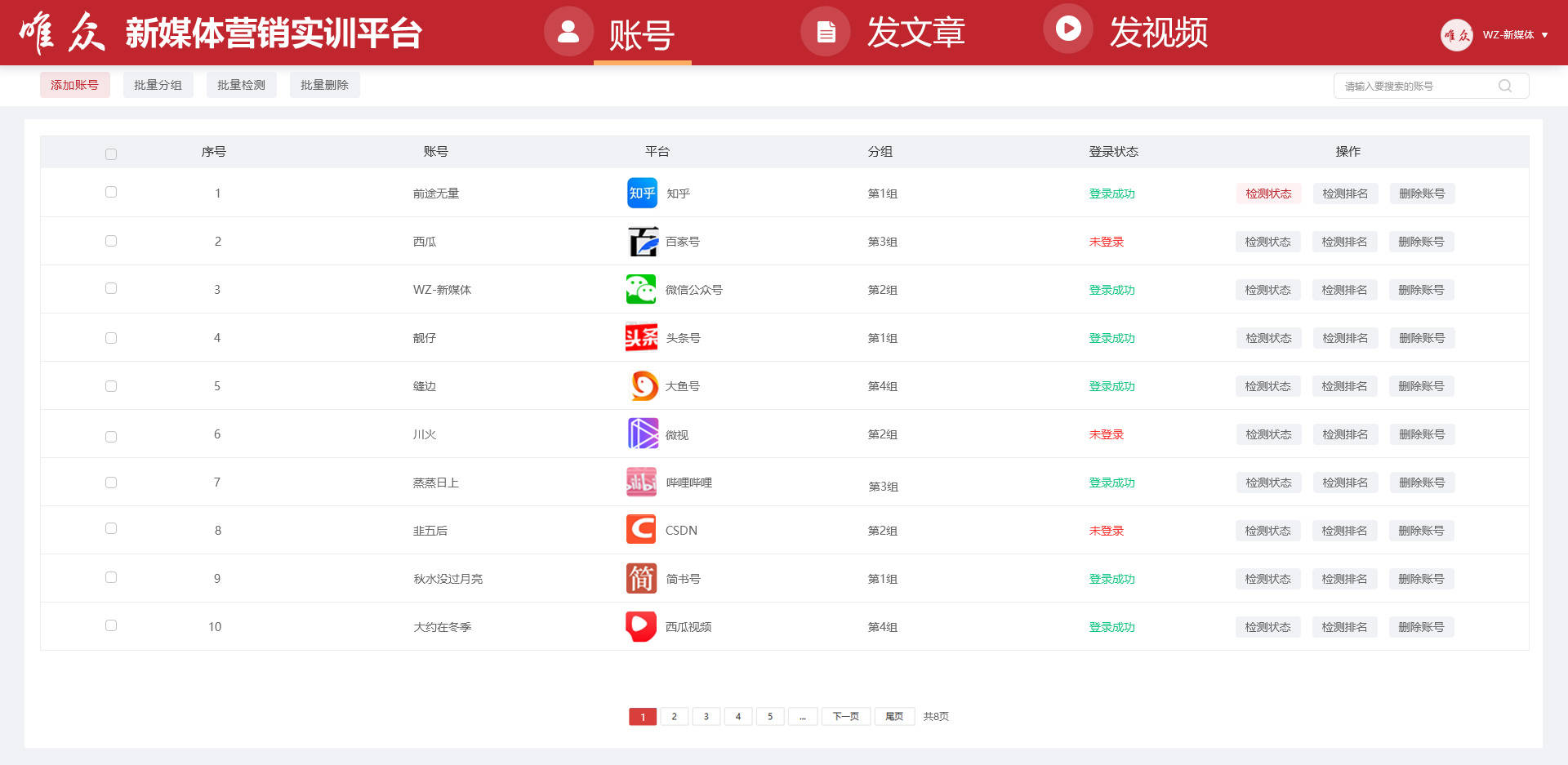
1. 账号管理:
提供统一便捷的账号管理功能,用户可随时添加、删除各平台账号,并进行灵活的账号分组管理。
系统自动检测登录状况,连续检测账号状态,确保用户及时了解账号的运行情况。
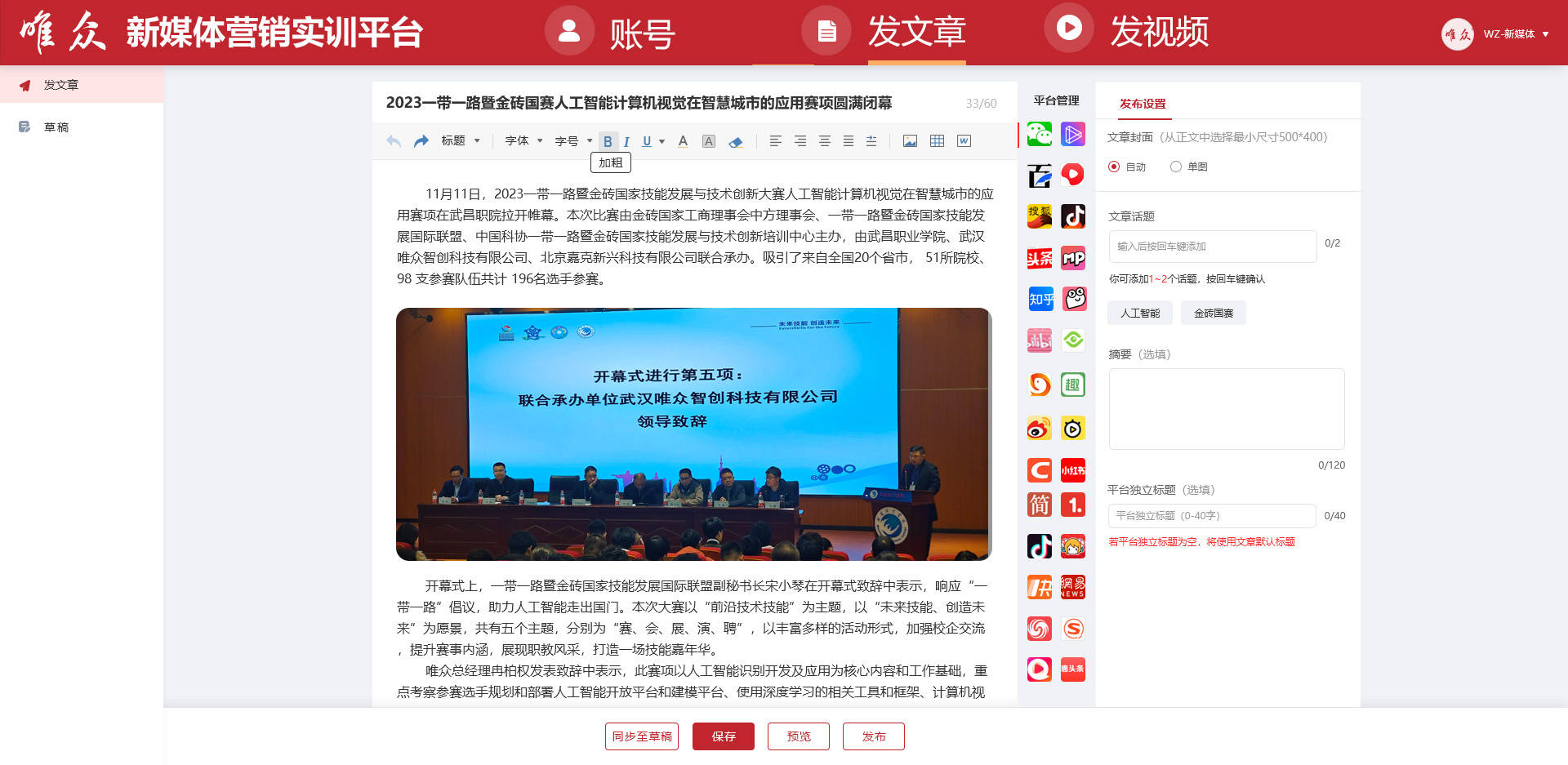
2. 文章编辑器:
提供强大的文章编辑器,支持Word导入,自动排版,实现快速内容编辑、图片插入和文档排版。
智能识别标题,辅助建立文档结构,提高编辑效率。
自动保存功能,实时保存用户正在创作的内容。
3. 平台设置:
提供统一的发布前平台设置界面,用户可根据不同平台的特点进行个性化设置,包括文章标题、分类、封面、标签等。
智能识别标签、自动分类等默认设置功能,简化用户操作,提高发布效率。
4. 一键发文章:
实现与多家热门新媒体、博客平台的技术对接,覆盖知名平台如百家号、搜狐号、公众号等。
用户只需一键发布,实现文章在各平台的同步推送,无需重复登录账号发布内容。
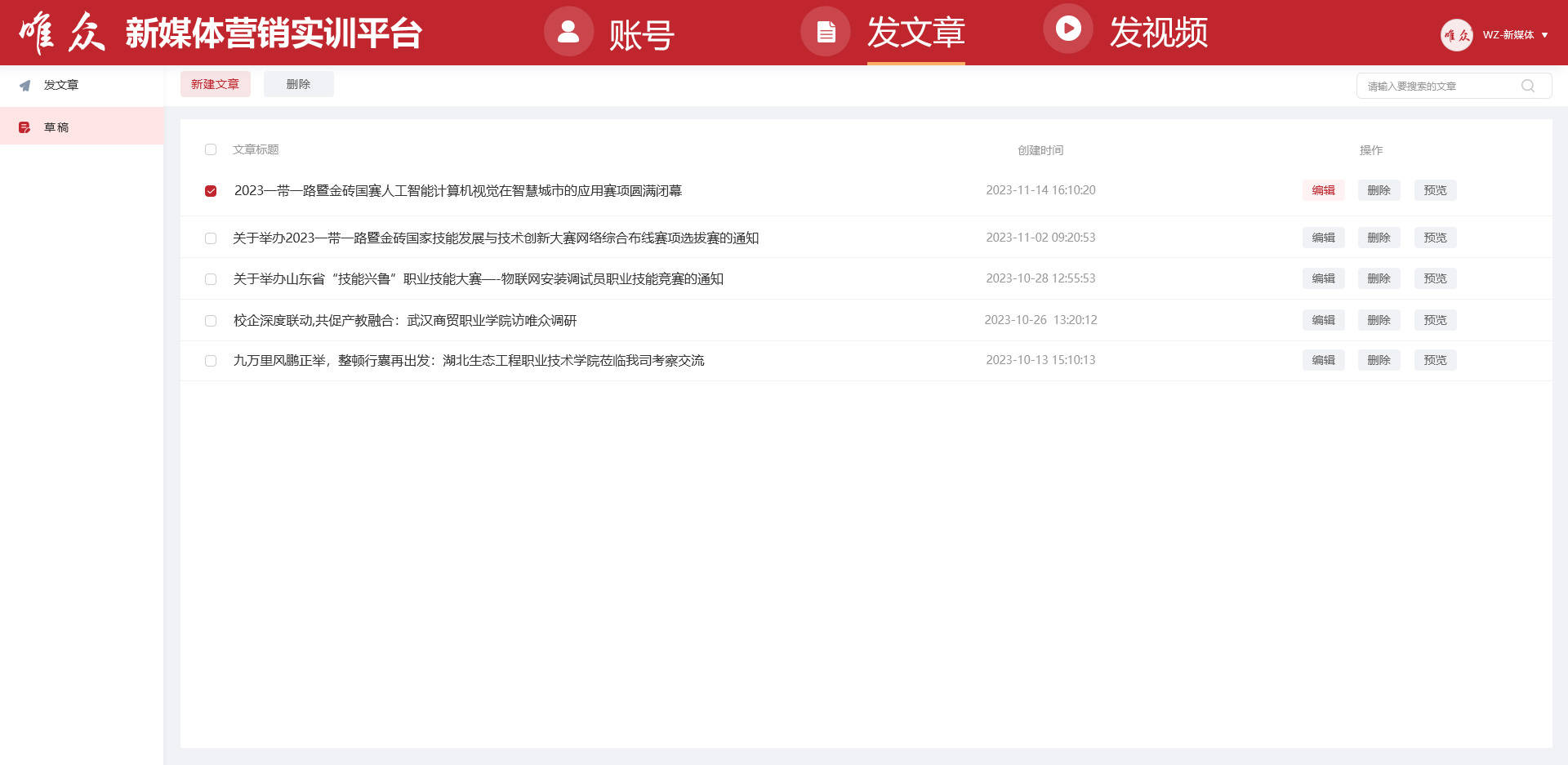
5. 我的文章:
提供统一的后台文章管理界面,用户可以轻松查看或删除已发布文章,查看发布详情如时间、平台和状态等信息。
草稿箱功能,用户可以保存草稿,并在草稿箱中查看和编辑未发布文章,提高创作效率。
通过《新媒体营销实训平台》,用户将更轻松地进行新媒体营销内容的管理和发布,实现高效、一站式的内容推广。
实训课程设置
新媒体基础知识: 学生需学习新媒体的基本概念、发展历程和市场趋势。
社交媒体运营: 通过实操学生如何在不同社交媒体平台上制定并执行有效的营销策略。
内容创作与编辑: 培养学生具备撰写各类营销内容、图文编辑和视频制作的能力。
数据分析与优化: 学生学习如何通过数据分析改进营销策略,提高活动效果。
实际案例分析: 分析真实案例,让学生了解不同行业的新媒体营销实践,拓展视野。
实训项目
社交媒体运营实战: 学生分组负责运营一个模拟企业社交媒体账号,从策划到执行全流程体验。
内容创作比赛: 组织学生进行内容创作比赛,评选最具创意和影响力的作品。
实时数据分析挑战: 设计实时数据分析挑战,让学生在限定时间内分析数据并提出优化建议。
行业合作项目: 与实际企业合作,让学生参与真实项目,锻炼实际操作能力。
实训师资力量
专业导师: 招聘有丰富实际经验的新媒体专业导师,确保学生能够获得实际操作指导。
行业合作导师: 与新媒体行业企业建立合作关系,邀请业内专业人士作为实训导师,传授实际操作技能。
评估体系
实训项目成果评估: 对学生在实训项目中的表现和成果进行定期评估。
模拟企业社交媒体账号运营效果: 对模拟企业社交媒体账号运营效果进行评估,包括粉丝增长、互动率等。
实时数据分析挑战评定: 对学生在实时数据分析挑战中的分析水平和解决问题的能力进行评定。
专业技能考核: 通过实际操作考核学生的新媒体管理、内容创作和数据分析等专业技能。
持续改进与更新
跟踪新媒体趋势: 不断更新实训室设备和课程内容,以跟上新媒体行业的发展趋势。
与企业保持合作: 与新媒体行业企业保持密切合作,获取最新的行业动态和实际需求。
定期师资培训: 为导师提供定期的新媒体领域培训,保证他们了解最新技术和市场动态。
通过以上全面而系统的高职新媒体营销实训室方案,学生将能够在毕业后顺利进入新媒体行业,为企业提供专业的营销服务。