网站里弹窗怎么做天津各区房价一览表
《关于如何防止edge浏览器偷取chrome浏览器的账号》
前段时间edge自动更新了,我并没有太在意界面的问题。但是由于我使用同一个网站平台时,例如b站,甚至是邮箱,edge的账号和chrome的账号会自动同步,这就导致我很难短时间内切换账号,亦或是同时登录两个账号。
It is quite ANNOYING.
于是就有了这篇杂谈博客。这里特别感谢知乎大佬的操作,这里仅用更加具象化的步骤,重述作者的操作。
1:建立新的网页,并跳转到以下地址
edge://settings/profiles/importBrowsingData/importOnLaunch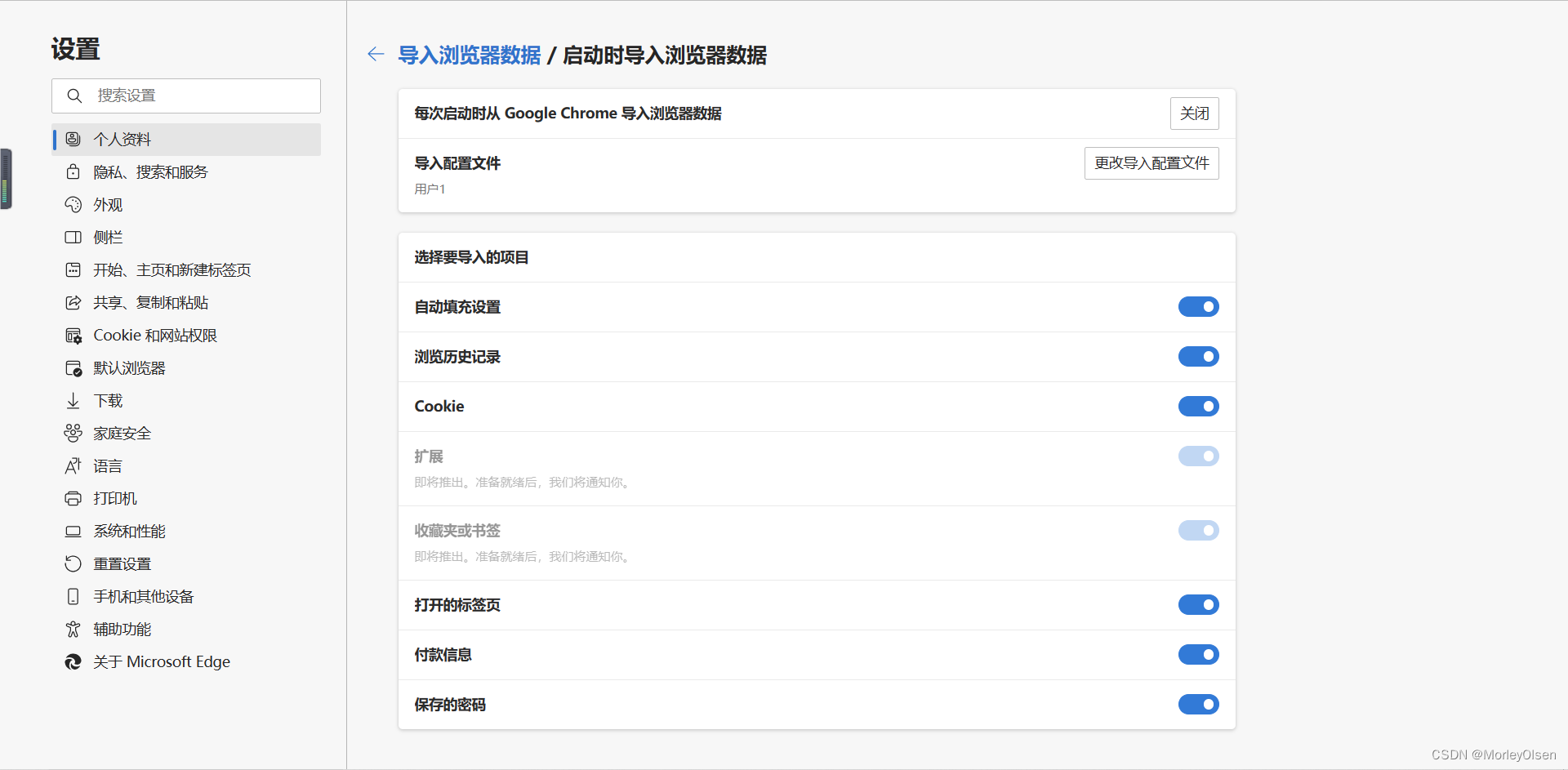
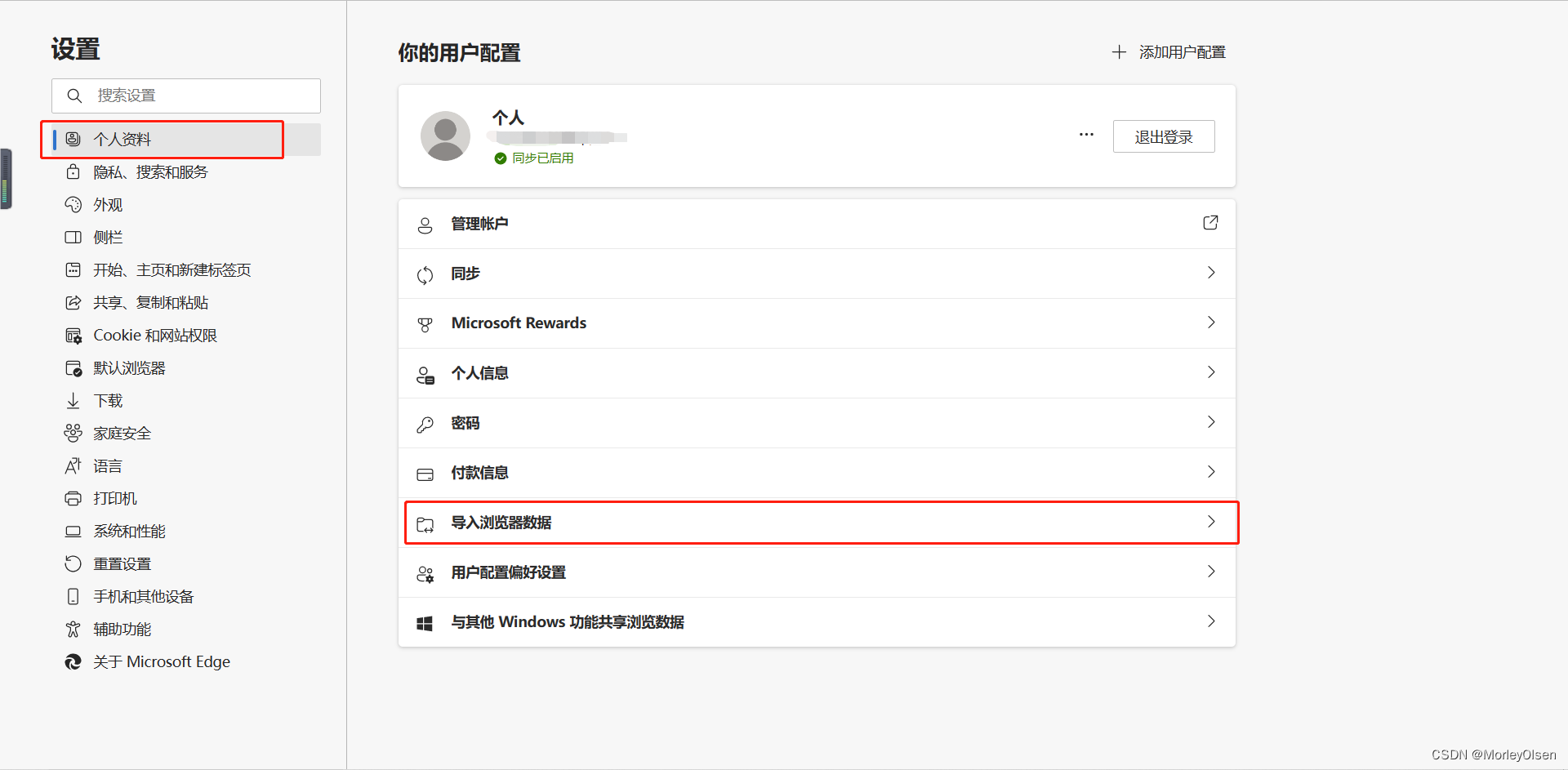
2:点击左边框的个人资料,再点击导入浏览器数据
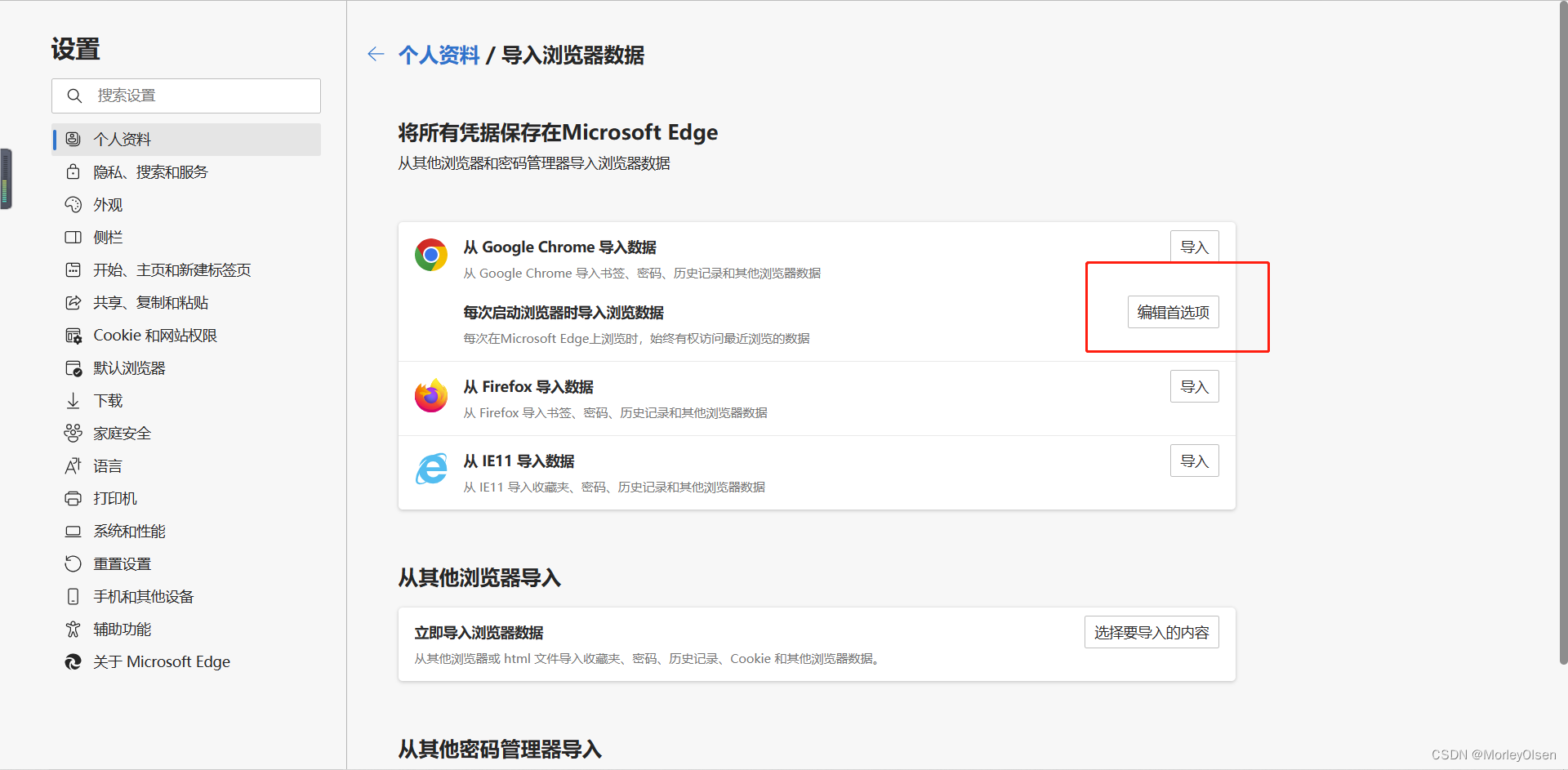
3:在chrome的地方,点击编辑首选项
4:第一栏的设置设置关闭,点击他
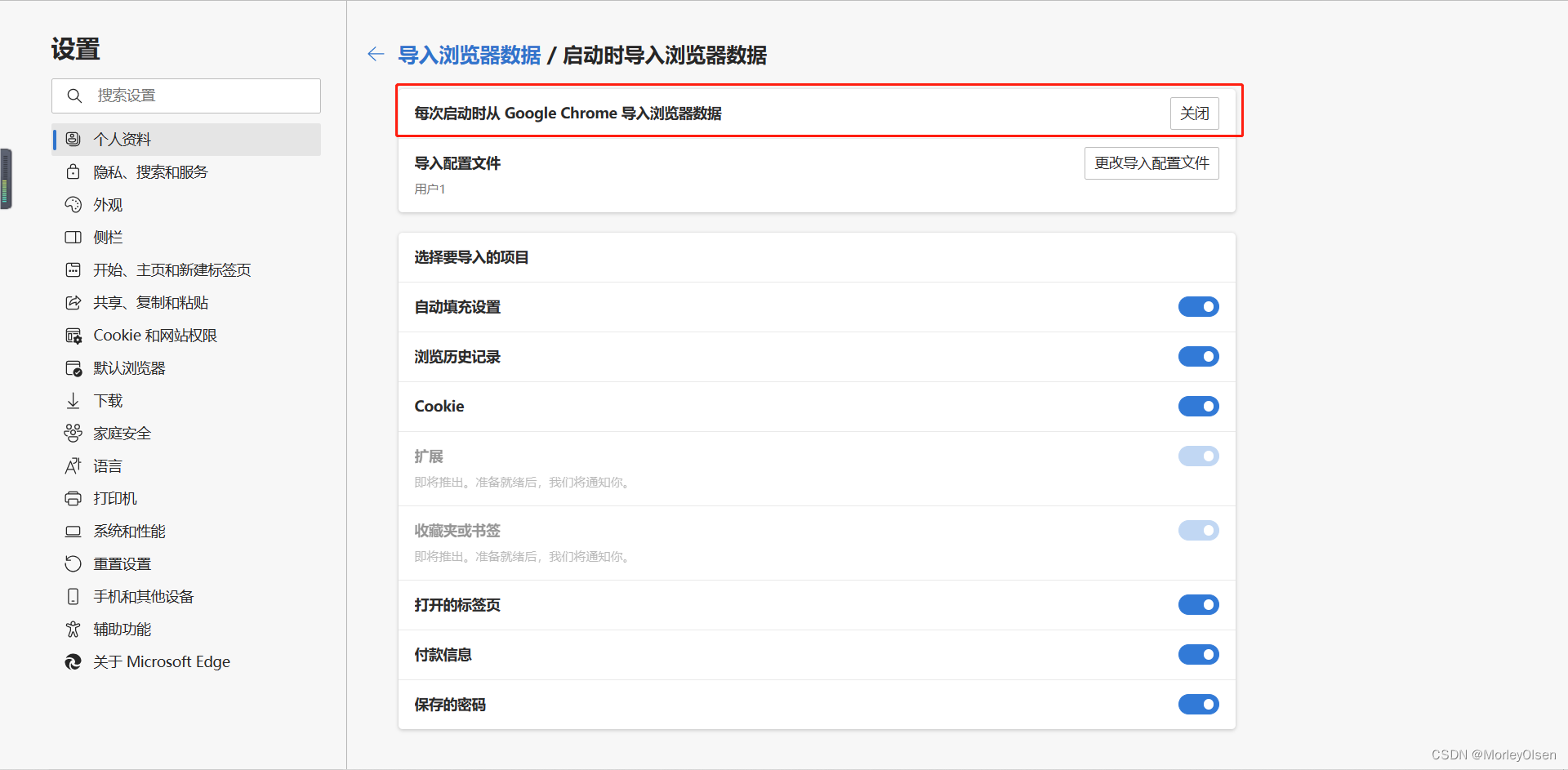
5:弹出的窗口,选择确认
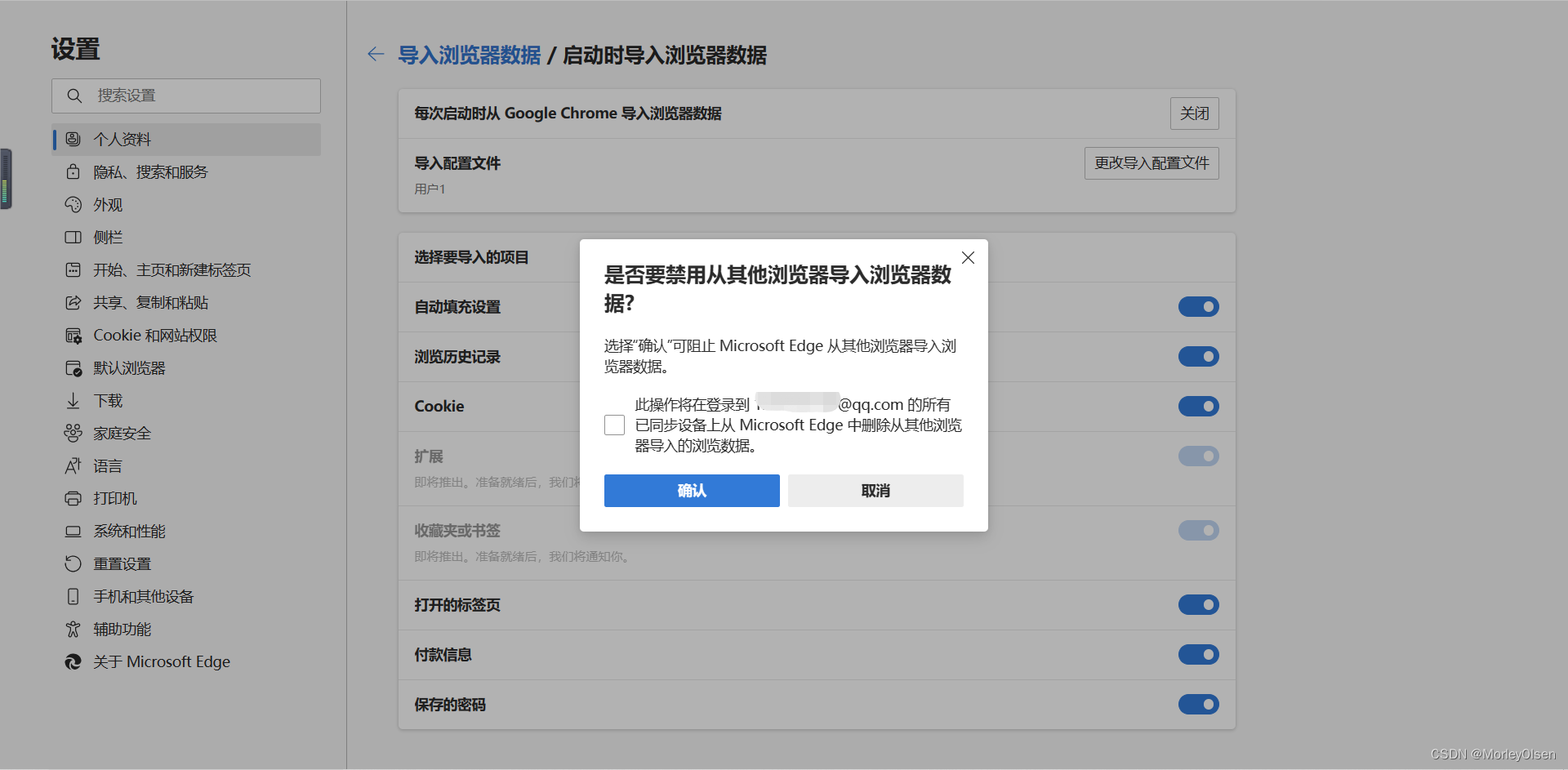
最后应该就可以了!上述操作来源于如何才能让CHROME和EDGE不关联? - 知乎 (zhihu.com)