开公司需要什么条件南京seo推广
Mybatis与Spring的集成
Mybatis是一款轻量级的ORM框架,而Spring是一个全栈式的框架,二者的结合可以让我们更加高效地进行数据持久化操作。
Mybatis与Spring的集成主要有两种方式:使用Spring的Mybatis支持和使用Mybatis的Spring支持。
使用Spring的Mybatis支持:
1. 在Spring的配置文件中配置数据源和事务管理器。
2. 在Mybatis的配置文件中定义数据源和事务管理器。
3. 在Spring的配置文件中定义SqlSessionFactory,将Mybatis的配置文件进行引入。
4. 在Spring的配置文件中定义MapperScannerConfigurer,用于扫描Mapper接口,并将其与SqlSessionFactory进行绑定。
使用Mybatis的Spring支持:
1. 在Spring的配置文件中配置数据源和事务管理器。
2. 在Mybatis的配置文件中定义数据源和事务管理器。
3. 在Spring的配置文件中定义MapperFactoryBean,将Mapper接口与SqlSessionFactory进行绑定。
无论使用哪种方式,我们都需要在Spring的配置文件中定义数据源、事务管理器和SqlSessionFactory。同时,我们还需要在Mybatis的配置文件中定义数据源和事务管理器。最后,我们需要将Mapper接口与SqlSessionFactory进行绑定,以便进行数据持久化操作,接下来我们开始实操
Spring-mybatis
选择我们的pom.xml配置文件,配置引用插件pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion><groupId>org.example</groupId>
<artifactId>Spring-mybatis</artifactId>
<version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><maven.compiler.plugin.version>3.7.0</maven.compiler.plugin.version><!--添加jar包依赖--><!--1.spring 5.0.2.RELEASE相关--><spring.version>5.0.2.RELEASE</spring.version><!--2.mybatis相关--><mybatis.version>3.4.5</mybatis.version><!--mysql--><mysql.version>5.1.44</mysql.version><!--pagehelper分页jar依赖--><pagehelper.version>5.1.2</pagehelper.version><!--mybatis与spring集成jar依赖--><mybatis.spring.version>1.3.1</mybatis.spring.version><!--3.dbcp2连接池相关 druid--><commons.dbcp2.version>2.1.1</commons.dbcp2.version><commons.pool2.version>2.4.3</commons.pool2.version><!--4.log日志相关--><log4j2.version>2.9.1</log4j2.version><!--5.其他--><junit.version>4.12</junit.version><servlet.version>4.0.0</servlet.version><lombok.version>1.18.2</lombok.version>
</properties><dependencies><!--1.spring相关--><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-orm</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-tx</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-web</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>${spring.version}</version></dependency><!--2.mybatis相关--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>${mybatis.version}</version></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><!--pagehelper分页插件jar包依赖--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>${pagehelper.version}</version></dependency><!--mybatis与spring集成jar包依赖--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>${mybatis.spring.version}</version></dependency><!--3.dbcp2连接池相关--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-dbcp2</artifactId><version>${commons.dbcp2.version}</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>${commons.pool2.version}</version></dependency><!--4.log日志相关依赖--><!--核心log4j2jar包--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j2.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j2.version}</version></dependency><!--web工程需要包含log4j-web,非web工程不需要--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-web</artifactId><version>${log4j2.version}</version></dependency><!--5.其他--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>${junit.version}</version><!-- <scope>test</scope>--></dependency><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>${servlet.version}</version><scope>provided</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><scope>provided</scope></dependency></dependencies><build><finalName>Spring-mybatis</finalName><resources><!--解决mybatis-generator-maven-plugin运行时没有将XxxMapper.xml文件放入target文件夹的问题--><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource><!--解决mybatis-generator-maven-plugin运行时没有将jdbc.properites文件放入target文件夹的问题--><resource><directory>src/main/resources</directory><includes><include>jdbc.properties</include><include>*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>${maven.compiler.plugin.version}</version><configuration><source>${maven.compiler.source}</source><target>${maven.compiler.target}</target><encoding>${project.build.sourceEncoding}</encoding></configuration></plugin><plugin><groupId>org.mybatis.generator</groupId><artifactId>mybatis-generator-maven-plugin</artifactId><version>1.3.2</version><dependencies><!--使用Mybatis-generator插件不能使用太高版本的mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency></dependencies><configuration><overwrite>true</overwrite></configuration></plugin><plugin><artifactId>maven-clean-plugin</artifactId><version>3.1.0</version></plugin><!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_war_packaging --><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.22.1</version></plugin><plugin><artifactId>maven-war-plugin</artifactId><version>3.2.2</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin></plugins>
</build></project>log4j2.xml
创建 log4j2.xml 配置文件,并且进行配置
<?xml version="1.0" encoding="UTF-8"?><!-- status : 指定log4j本身的打印日志的级别.ALL< Trace < DEBUG < INFO < WARN < ERROR < FATAL < OFF。 monitorInterval : 用于指定log4j自动重新配置的监测间隔时间,单位是s,最小是5s. -->
<Configuration status="WARN" monitorInterval="30"><Properties><!-- 配置日志文件输出目录 ${sys:user.home} --><Property name="LOG_HOME">/root/workspace/lucenedemo/logs</Property><property name="ERROR_LOG_FILE_NAME">/root/workspace/lucenedemo/logs/error</property><property name="WARN_LOG_FILE_NAME">/root/workspace/lucenedemo/logs/warn</property><property name="PATTERN">%d{yyyy-MM-dd HH:mm:ss.SSS} [%t-%L] %-5level %logger{36} - %msg%n</property></Properties><Appenders><!--这个输出控制台的配置 --><Console name="Console" target="SYSTEM_OUT"><!-- 控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) --><ThresholdFilter level="trace" onMatch="ACCEPT"onMismatch="DENY" /><!-- 输出日志的格式 --><!-- %d{yyyy-MM-dd HH:mm:ss, SSS} : 日志生产时间 %p : 日志输出格式 %c : logger的名称 %m : 日志内容,即 logger.info("message") %n : 换行符 %C : Java类名 %L : 日志输出所在行数 %M : 日志输出所在方法名 hostName : 本地机器名 hostAddress : 本地ip地址 --><PatternLayout pattern="${PATTERN}" /></Console><!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用 --><!--append为TRUE表示消息增加到指定文件中,false表示消息覆盖指定的文件内容,默认值是true --><File name="log" fileName="logs/test.log" append="false"><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /></File><!-- 这个会打印出所有的info及以下级别的信息,每次大小超过size, 则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档 --><RollingFile name="RollingFileInfo" fileName="${LOG_HOME}/info.log"filePattern="${LOG_HOME}/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log"><!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) --><ThresholdFilter level="info" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><!-- 基于时间的滚动策略,interval属性用来指定多久滚动一次,默认是1 hour。 modulate=true用来调整时间:比如现在是早上3am,interval是4,那么第一次滚动是在4am,接着是8am,12am...而不是7am. --><!-- 关键点在于 filePattern后的日期格式,以及TimeBasedTriggeringPolicy的interval, 日期格式精确到哪一位,interval也精确到哪一个单位 --><!-- log4j2的按天分日志文件 : info-%d{yyyy-MM-dd}-%i.log --><TimeBasedTriggeringPolicy interval="1"modulate="true" /><!-- SizeBasedTriggeringPolicy:Policies子节点, 基于指定文件大小的滚动策略,size属性用来定义每个日志文件的大小. --><!-- <SizeBasedTriggeringPolicy size="2 kB" /> --></Policies></RollingFile><RollingFile name="RollingFileWarn" fileName="${WARN_LOG_FILE_NAME}/warn.log"filePattern="${WARN_LOG_FILE_NAME}/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log"><ThresholdFilter level="warn" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><TimeBasedTriggeringPolicy /><SizeBasedTriggeringPolicy size="2 kB" /></Policies><!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件,这里设置了20 --><DefaultRolloverStrategy max="20" /></RollingFile><RollingFile name="RollingFileError" fileName="${ERROR_LOG_FILE_NAME}/error.log"filePattern="${ERROR_LOG_FILE_NAME}/$${date:yyyy-MM}/error-%d{yyyy-MM-dd-HH-mm}-%i.log"><ThresholdFilter level="error" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><!-- log4j2的按分钟 分日志文件 : warn-%d{yyyy-MM-dd-HH-mm}-%i.log --><TimeBasedTriggeringPolicy interval="1"modulate="true" /><!-- <SizeBasedTriggeringPolicy size="10 MB" /> --></Policies></RollingFile></Appenders><!--然后定义logger,只有定义了logger并引入的appender,appender才会生效 --><Loggers><!--过滤掉spring和mybatis的一些无用的DEBUG信息 --><logger name="org.springframework" level="INFO"></logger><logger name="org.mybatis" level="INFO"></logger><!-- 第三方日志系统 --><logger name="org.springframework" level="ERROR" /><logger name="org.hibernate" level="ERROR" /><logger name="org.apache.struts2" level="ERROR" /><logger name="com.opensymphony.xwork2" level="ERROR" /><logger name="org.jboss" level="ERROR" /><!-- 配置日志的根节点 --><root level="all"><appender-ref ref="Console" /><appender-ref ref="RollingFileInfo" /><appender-ref ref="RollingFileWarn" /><appender-ref ref="RollingFileError" /></root></Loggers></Configuration>jdbc.properties
jdbc.properties用与文件辅助mysql数据库的连接
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://47.100.191.44:3308/mybatis_ssm?useUnicode=true&characterEncoding=UTF-8
jdbc.username=test01
jdbc.password=test01generatorConfig.xml
generatorConfig.xml 配置文件,用来引用插件自动生成类,接口,xml配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" >
<generatorConfiguration><!-- 引入配置文件 --><properties resource="jdbc.properties"/><!--指定数据库jdbc驱动jar包的位置--><classPathEntry location="D:\\temp\\mvn_repository\\mysql\\mysql-connector-java\\5.1.44\\mysql-connector-java-5.1.44.jar"/><!-- 一个数据库一个context --><context id="infoGuardian"><!-- 注释 --><commentGenerator><property name="suppressAllComments" value="true"/><!-- 是否取消注释 --><property name="suppressDate" value="true"/> <!-- 是否生成注释代时间戳 --></commentGenerator><!-- jdbc连接 --><jdbcConnection driverClass="${jdbc.driver}"connectionURL="${jdbc.url}" userId="${jdbc.username}" password="${jdbc.password}"/><!-- 类型转换 --><javaTypeResolver><!-- 是否使用bigDecimal, false可自动转化以下类型(Long, Integer, Short, etc.) --><property name="forceBigDecimals" value="false"/></javaTypeResolver><!-- 01 指定javaBean生成的位置 --><!-- targetPackage:指定生成的model生成所在的包名 --><!-- targetProject:指定在该项目下所在的路径 --><javaModelGenerator targetPackage="com.junlinyi.model"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/><!-- 是否对model添加构造函数 --><property name="constructorBased" value="true"/><!-- 是否针对string类型的字段在set的时候进行trim调用 --><property name="trimStrings" value="false"/><!-- 建立的Model对象是否 不可改变 即生成的Model对象不会有 setter方法,只有构造方法 --><property name="immutable" value="false"/></javaModelGenerator><!-- 02 指定sql映射文件生成的位置 --><sqlMapGenerator targetPackage="com.junlinyi.mapper"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/></sqlMapGenerator><!-- 03 生成XxxMapper接口 --><!-- type="ANNOTATEDMAPPER",生成Java Model 和基于注解的Mapper对象 --><!-- type="MIXEDMAPPER",生成基于注解的Java Model 和相应的Mapper对象 --><!-- type="XMLMAPPER",生成SQLMap XML文件和独立的Mapper接口 --><javaClientGenerator targetPackage="com.junlinyi.mapper"targetProject="src/main/java" type="XMLMAPPER"><!-- 是否在当前路径下新加一层schema,false路径com.oop.eksp.user.model, true:com.oop.eksp.user.model.[schemaName] --><property name="enableSubPackages" value="false"/></javaClientGenerator><!-- 配置表信息 --><!-- schema即为数据库名 --><!-- tableName为对应的数据库表 --><!-- domainObjectName是要生成的实体类 --><!-- enable*ByExample是否生成 example类 --><!--<table schema="" tableName="t_book" domainObjectName="Book"--><!--enableCountByExample="false" enableDeleteByExample="false"--><!--enableSelectByExample="false" enableUpdateByExample="false">--><!--<!– 忽略列,不生成bean 字段 –>--><!--<!– <ignoreColumn column="FRED" /> –>--><!--<!– 指定列的java数据类型 –>--><!--<!– <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> –>--><!--</table>--><table schema="" tableName="t_mvc_book" domainObjectName="Book"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"><!-- 忽略列,不生成bean 字段 --><!-- <ignoreColumn column="FRED" /> --><!-- 指定列的java数据类型 --><!-- <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> --></table></context>
</generatorConfiguration>spring-context.xml
spring-context.xml 配置文件,用来配置文件加载到spring的上下文
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!-- spring框架和mybatis进行整合的配置文件加载到spring的上下文中-->
<import resource="classpath:spring-mybatis.xml"></import></beans>spring-mybatis.xml
spring-mybatis.xml 配置文件,用来spring和MyBatis整合及自动识别类及方法
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"><!--1. 注解式开发 --><!-- 注解驱动 --><context:annotation-config/><!-- 用注解方式注入bean,并指定查找范围:com.junlinyi及子子孙孙包--><context:component-scan base-package="com.junlinyi"/><context:property-placeholder location="classpath:jdbc.properties"/><bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource"destroy-method="close"><property name="driverClassName" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/><!--初始连接数--><property name="initialSize" value="10"/><!--最大活动连接数--><property name="maxTotal" value="100"/><!--最大空闲连接数--><property name="maxIdle" value="50"/><!--最小空闲连接数--><property name="minIdle" value="10"/><!--设置为-1时,如果没有可用连接,连接池会一直无限期等待,直到获取到连接为止。--><!--如果设置为N(毫秒),则连接池会等待N毫秒,等待不到,则抛出异常--><property name="maxWaitMillis" value="-1"/></bean><!--4. spring和MyBatis整合 --><!--1) 创建sqlSessionFactory--><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><!-- 指定数据源 --><property name="dataSource" ref="dataSource"/><!-- 自动扫描XxxMapping.xml文件,**是任意路径 --><property name="mapperLocations" value="classpath*:com/junlinyi/**/mapper/*.xml"/><!-- 指定别名 --><property name="typeAliasesPackage" value="com/junlinyi/**/model"/><!--配置pagehelper插件--><property name="plugins"><array><bean class="com.github.pagehelper.PageInterceptor"><property name="properties"><value>helperDialect=mysql</value></property></bean></array></property></bean><!--2) 自动扫描com/junlinyi/**/mapper下的所有XxxMapper接口(其实就是DAO接口),并实现这些接口,--><!-- 即可直接在程序中使用dao接口,不用再获取sqlsession对象--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><!--basePackage 属性是映射器接口文件的包路径。--><!--你可以使用分号或逗号 作为分隔符设置多于一个的包路径--><property name="basePackage" value="com/junlinyi/**/mapper"/><property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/></bean><bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource" /></bean><tx:annotation-driven transaction-manager="transactionManager" /><aop:aspectj-autoproxy/>
</beans>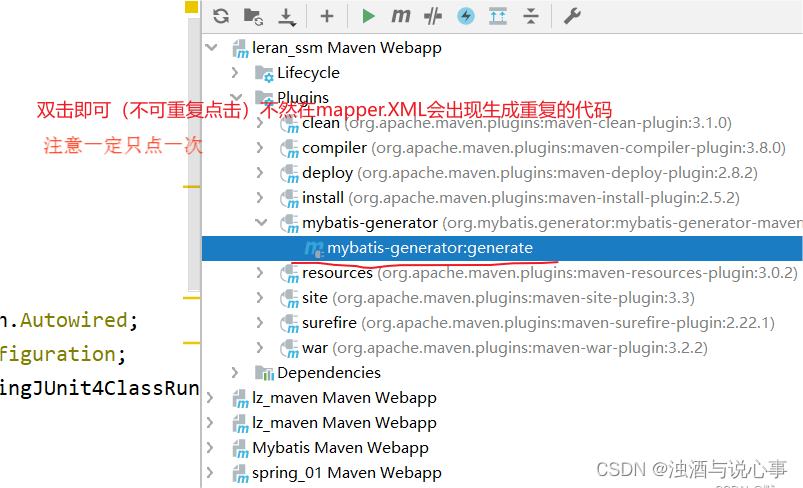
BookBiz
package com.junlinyi.biz;import com.zhanghao.model.Book;
import com.zhanghao.utils.PageBean;import java.util.List;/*** @author zhanghao* @site www.zhanghao.jly* @company s集团* @create 2023-08-25 16:33*/
public interface BookBiz {int deleteByPrimaryKey(Integer bid);int insert(Book record);int insertSelective(Book record);Book selectByPrimaryKey(Integer bid);int updateByPrimaryKeySelective(Book record);int updateByPrimaryKey(Book record);}BookBizImpl
package com.zhnaghao.biz.impl;import com.zhnaghao.biz.BookBiz;
import com.zhnaghao.mapper.BookMapper;
import com.zhnaghao.model.Book;
import com.zhnaghao.utils.PageBean;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;
import java.util.Map;/*** @author zhnaghao* @site www.zhnaghao.jly* @company s集团* @create 2023-08-25 16:34*/
@Service
public class BookBizImpl implements BookBiz {//相当于set及get@Autowiredprivate BookMapper bookMapper;private Book book;private PageBean pageBean;@Overridepublic int deleteByPrimaryKey(Integer bid) {return bookMapper.deleteByPrimaryKey(bid);}@Overridepublic int insert(Book record) {return bookMapper.insert(record);}@Overridepublic int insertSelective(Book record) {return bookMapper.insertSelective(record);}@Overridepublic Book selectByPrimaryKey(Integer bid) {return bookMapper.selectByPrimaryKey(bid);}@Overridepublic int updateByPrimaryKeySelective(Book record) {return bookMapper.updateByPrimaryKeySelective(record);}@Overridepublic int updateByPrimaryKey(Book record) {return bookMapper.updateByPrimaryKey(record);}}BookBizImplTest
package com.zhanghao.biz.impl;import com.zhanghao.biz.BookBiz;
import com.zhanghao.model.Book;
import com.zhanghao.utils.PageBean;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import static org.junit.Assert.*;/*** @author zhanghao* @site www.zhanghao.jly* @company s集团* @create 2023-08-25 16:39*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations={"classpath:spring-context.xml"})
public class BookBizImplTest {@Autowiredprivate BookBiz bookBiz;@Beforepublic void setUp() throws Exception {}@Afterpublic void tearDown() throws Exception {}@Testpublic void deleteByPrimaryKey() {System.out.println(bookBiz.deleteByPrimaryKey(1));}@Testpublic void insertSelective() {int i = bookBiz.insertSelective(new Book(1, "第一章开局送老婆", 99.9f));System.out.println(i);}@Testpublic void selectByPrimaryKey() {System.out.println(bookBiz.selectByPrimaryKey(63));}@Testpublic void updateByPrimaryKeySelective() {int i = bookBiz.updateByPrimaryKeySelective(new Book(1, "第一章开局送老婆和房子", 999.9f));//修改后进行查看System.out.println(bookBiz.selectByPrimaryKey(1));}}