建筑工程找工作哪个网站好网页美工制作网站
S函数介绍
S函数中使用文本方式输入公式和方程,适合复杂动态系统的数学描述,并且在仿真过程中可以对仿真参数进行更精确的描述。
S函数模块是整个Simulink动态系统的核心。
S函数时系统函数(system function)的简称,是指采用非图形化的方式描述的一个功能模块。用户可以采用MATLAB代码、C、C++等语言编写S函数。S函数由一种特定的语法构成,用来描述并实现连续系统、离散系统和复合系统等动态系统。S函数能够接受来自Simulink求解器的相关信息,并对求解器发出的命令做出适当的响应,这种交互作用非常类似Simulink系统模块与求解器的交互作用。一个结构体系完整的S函数包含了描述动态系统所需的全部能力,所有其他的使用情况都是这个结构体系的特例。
S函数使用步骤
一般而言,S函数的使用步骤如下:
(1)创建S函数源文件。创建S函数源文件有多种方法,Simulink提供了很多S函数模板和例子,用户可以根据自己的需要修改相应的模板或例子即可。
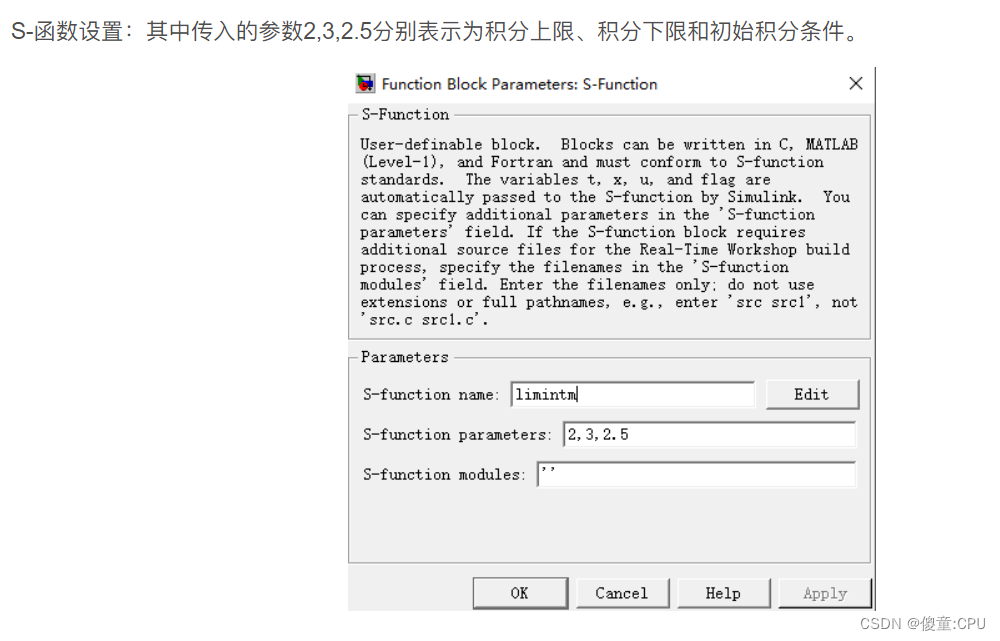
(2)在动态系统的Simulink模型框图中添加S-funtion模块,并进行正确的设置。
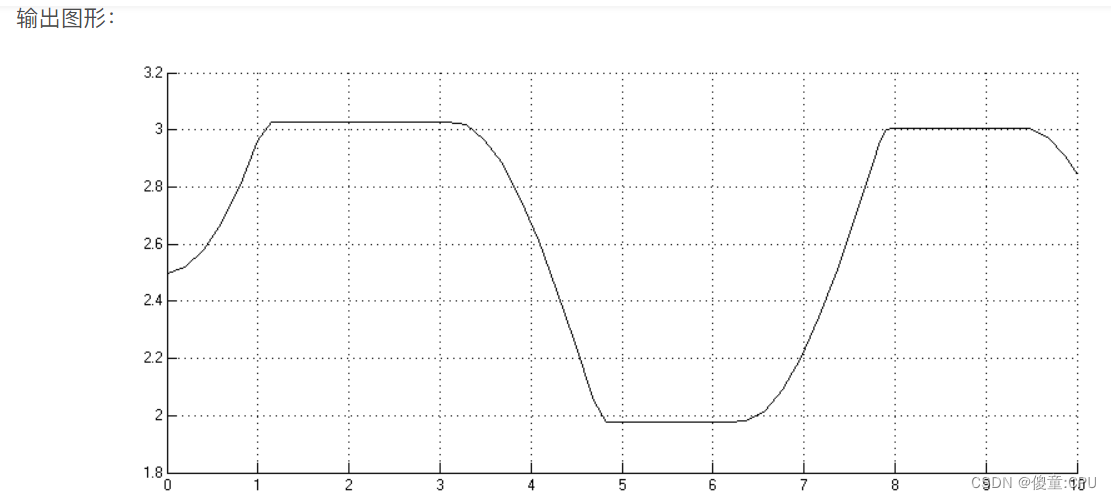
(3)在Simulink模型框图中按照定义好的功能连接输入/输出端口