今天开始写一些高并发实战系列。
本系列主要讲两大主流框架:
Netty和Quasar(java纤程库)
先介绍netty吧,netty是业界比较成熟的高性能异步NIO框架。
简单来说,它就是对NIO2的封装,但提供了更好用,bug更少的API。
为什么netty能提供高性能?核心要点有以下两点:
1.Netty基于NIO2的事件驱动模式
2.零拷贝
先说,事件驱动模式吧,这个好理解,我们慢慢分解:
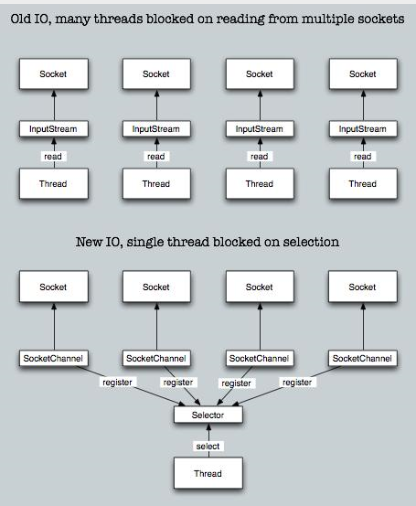
java原来IO操作都是阻塞的,一个IO请求一个线程,多个IO请求就要多个线程,很消耗资源。
现在NIO不一样了,多个IO请求,一个线程(reactor),这个线程专门用来监听不同事件(read,write,accept),根据事件类型分发到不同线程去异步处理,处理完后拿到结果返回给客户端。原理如下图:
举个例子吧:比如你去KFC买汉堡,
1.如果是阻塞式IO的情景,是这样的:
你:美女,给我来个鸡腿堡,不要辣。
服务员小姜:好的,稍等。
然后服务员小姜,就去后台。先炸鸡腿,再烤面包,再把鸡腿放些沙拉酱,合上两处面包,再用纸打个包。
最后,服务员小姜,一路小跑,到前台,把汉堡放在托盘上。
然后,小姜打开电脑跟你结账:您好,一共19.9,谢谢。
2.如果是非阻塞式NIO的情景,是这样的:
你:美女,给我来个鸡腿堡,不要辣。
服务员小姜:好的,稍等。回头一喊:老姜,给我来个鸡腿堡。
然后服务员老姜,就去后台。先炸鸡腿,再烤面包,再把鸡腿放些沙拉酱,合上两处面包,再用纸打个包。
最后,服务员老姜,一路小跑,到前台,把汉堡交给小姜,小姜把汉堡放在托盘上。
然后,小姜打开电脑跟你结账:您好,一共19.9,送你一包薯条,谢谢。
这两种情景,有什么不一样?

有同学说,前面的情景,只有小姜一个人在干活,很着挺累人的。而且,貌似,小姜,同一时间,只能服务一个客户。
也有同学说,后面加上老姜,小姜的工作轻松很多,也可以同进服务多个客户,效率也提高了不少。
也有同学说,后面小姜,还送了一包薯条!-------好眼力,好细心!这都被你发现了!但这个不是问题的重点!年轻人不要分心啊!
这两个场景,完全说明了一个问题:
阻塞式IO效率很低,等待时间长,吞吐量低;非阻塞式NIO效率高,等待时间短(后台可以用N个老姜),吞吐量高。
从上面的例子我们也可以很容易理解事件驱动模式。
什么叫事件驱动?
首先,要有事件:你要点个鸡腿堡,这是个事件。
然后,这个事件被小姜“监听”到了,这时,小姜的身份类似于NIO的selector(监听器)。
小姜,一监听到这个事件,立马转发给老姜(worker线程),老姜在后面忙活,然后没有说话,扔给小姜一个:打包好的鸡腿堡。
小姜再转扔给你。
这就叫事件驱动模式。
现在我们再到说说什么是BIO,NIO,AIO,以及它们的区别和应用场景。
-
Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
-
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
-
Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
BIO、NIO、AIO适用场景分析:
-
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
-
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
-
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
另外,I/O属于底层操作,需要操作系统支持,并发也需要操作系统的支持,所以性能方面不同操作系统差异会比较明显。
在高性能的I/O设计中,有两个比较著名的模式Reactor和Proactor模式,其中Reactor模式用于同步I/O,而Proactor运用于异步I/O操作。
好了,今天的内容就这些,明天继续讲零拷贝。
对了,点汉堡时,别忘了跟服务员多要包薯条,毕竟这是免费的!:)