如何做网站方案惠州网站制作公司哪家好
一、python官网及下载路径
官网地址:Welcome to Python.org
下载路径:Download Python | Python.org

linux源码安装包下载:
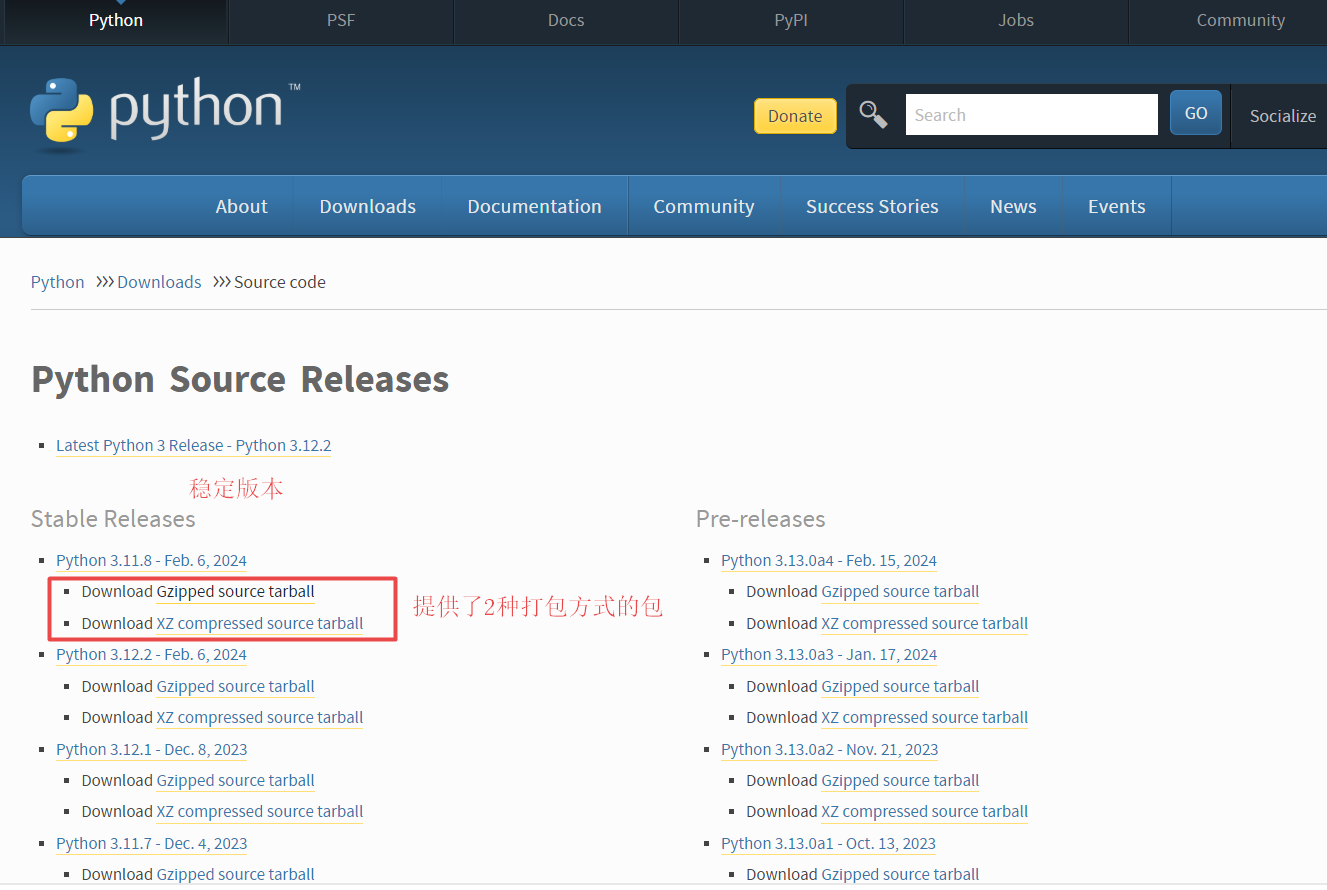
windows二进制安装包下载:
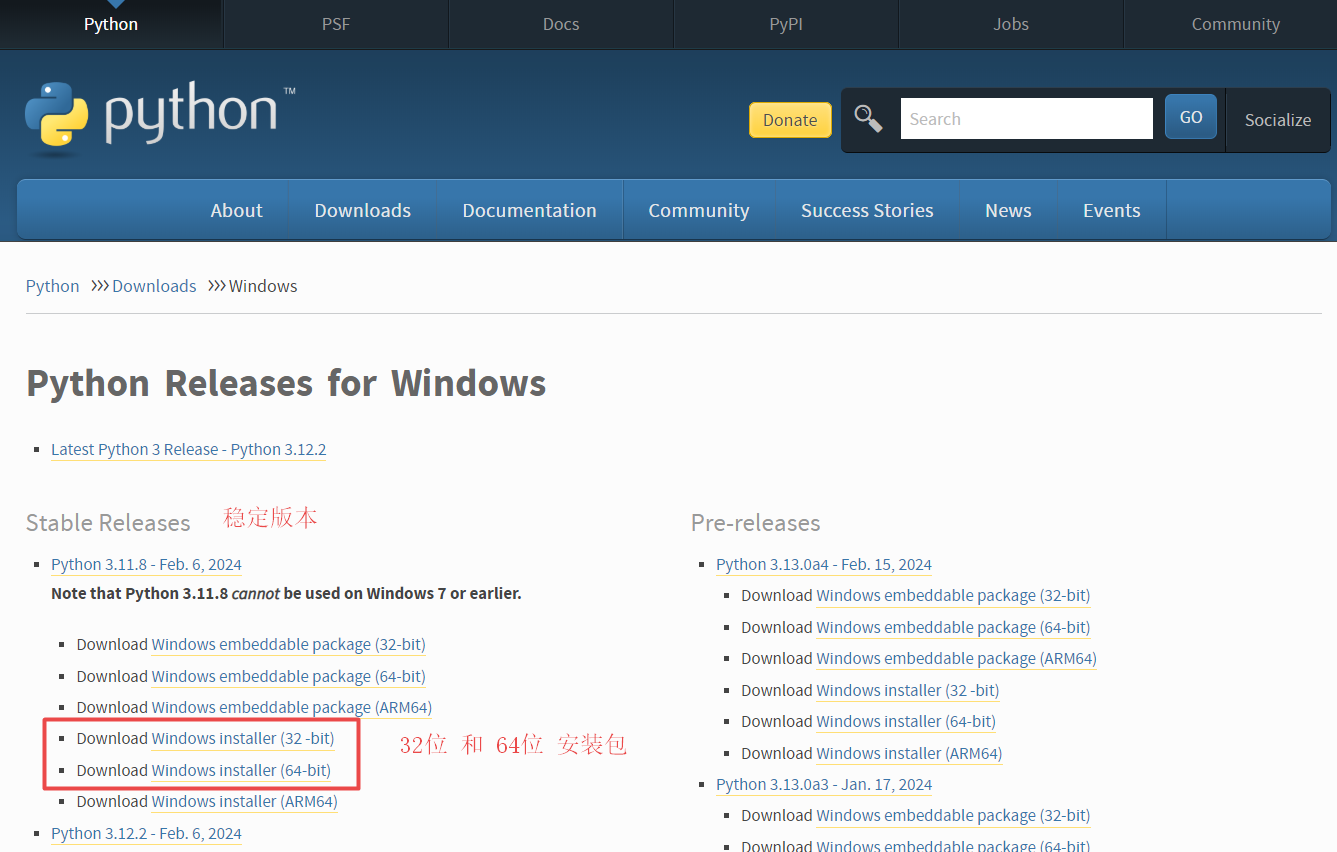
二、Linux如何安装python
2.1 单版本安装
以安装python3.9.7源码包为例。
2.1.1 下载安装包
$ wget https://www.python.org/ftp/python/3.9.7/Python-3.9.7.tgz
2.1.2 解压安装
$ tar -zxvf Python-3.9.7.tar.xz #解压安装包 $ mkdir /usr/local/python3 # 创建编译安装目录 $ cd Python-3.9.7 # 进入python的解压目录 $ ./configure --prefix=/usr/local/python3 --with-ssl --enable-optimizations $ make && make install # 编译安装
2.1.3 配置python3的软链接
ln -sf /usr/local/python3/bin/python3.9 /usr/bin/python3 ln -sf /usr/local/python3/bin/pip3.9 /usr/bin/pip3
2.1.4 验证是否安装成功
python3 -V pip3 -V
正常输出版本号,表示安装成功!
2.2 多版本安装方式
测试环境提供一台机器给开发使用,不同的开发人员需要使用不同版本的Python。故在每个用户在自己的/home目录下使用源码安装自己所需要的Python版本。
# 使用python源码安装,一些操作系统依赖包。可以自行选择yum安装。
yum install -y nc screen lrzsz expect cmake make gcc gcc-c++ perl bison bc thread libaio libaio-devel zlib zlib-devel nc python python-devel cmake ncurses-devel scurses sysstat perl-ExtUtils-CBuilder perl-CPAN perl-Log-Dispatch perl-Config-Tiny perl-Parallel-ForkManager perl-Config IniFiles vim-enhanced ftp telnet wget tree iftop iotop fio bind-utils net-tools openssl openssl-devel libnl-3-devel libnl-3 libnl libnl-devel glib glibc-devel glib-devel pcre pcre-devel openssl openssl-devel dos2unix dstat iftop iotop gcc gcc-c++ make cmake automake autoconf libxml2 libxml2-devel zlib zlib-devel ncurses ncurses-devel numactl-devel numactl ftp dstat wget make iftop iotop dstat bzip2-devel以安装python2.7.13源码包为例。
2.2.1 下载软件包
$ wget https://www.python.org/ftp/python/2.7.13/Python-2.7.13.tgz
2.2.2 解压安装
$ tar zxvf Python-2.7.13.tgz
$ cd Python-2.7.13
$ ./configure --prefix=/home/mgx/python2.7.13 --with-ssl --enable-optimizations
$ make –j4
$ make install
2.2.3 配置个人环境变量
$ vim ~/.bashrc
# 加上这一行
PATH=/home/mgx/python2.7.13/bin:$PATH
让环境变量生效
$ source ~/.bashrc
查看Python版本
$ python –V
升级pip
$ pip install --upgrade pip
三、windows如何安装python
3.1 安装
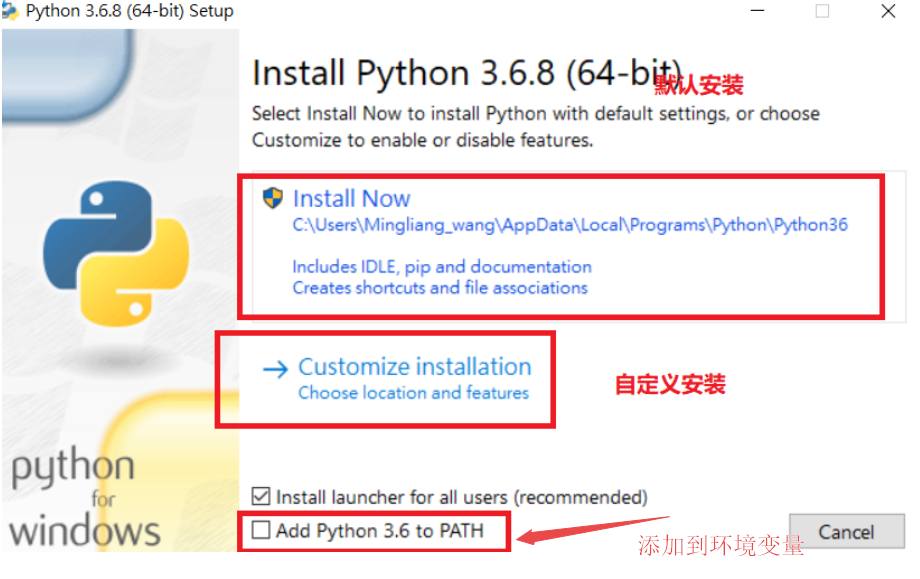
安装比较简单,只需默认下一步即可完成安装。网上安装教程多的不可数,这里就不浪费时间重复了。关键的几步:
- 安装路劲是默认安装 还是自定义安装。 默认安装的路径:C:\Users\use\AppData\Local\Programs\Python
默认安装的第三方库安装路径: C:\Users\use\AppData\Local\Programs\Python\Python310\Lib\site-packages - Add Python 3.6 to PATH这样安装好后,直接在cmd小黑框即可执行调用python。
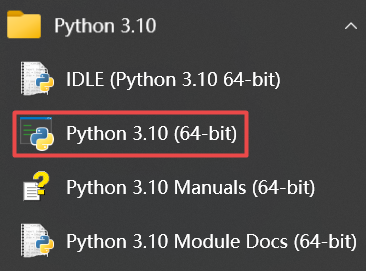
安装成功后的结果:IDLE 是交互式开发环境 ,常用的就是黑色图标的这个了。
3.2 运行方式
1)打开 IDLE 运行
2)按 Win+R 打开运行,输入 cmd 回车,在打开的命令行中,直接输入 python 回车。
3.3 pycharm 解释器设置
File-->Settings-->Project Settings-->Python Interpreter
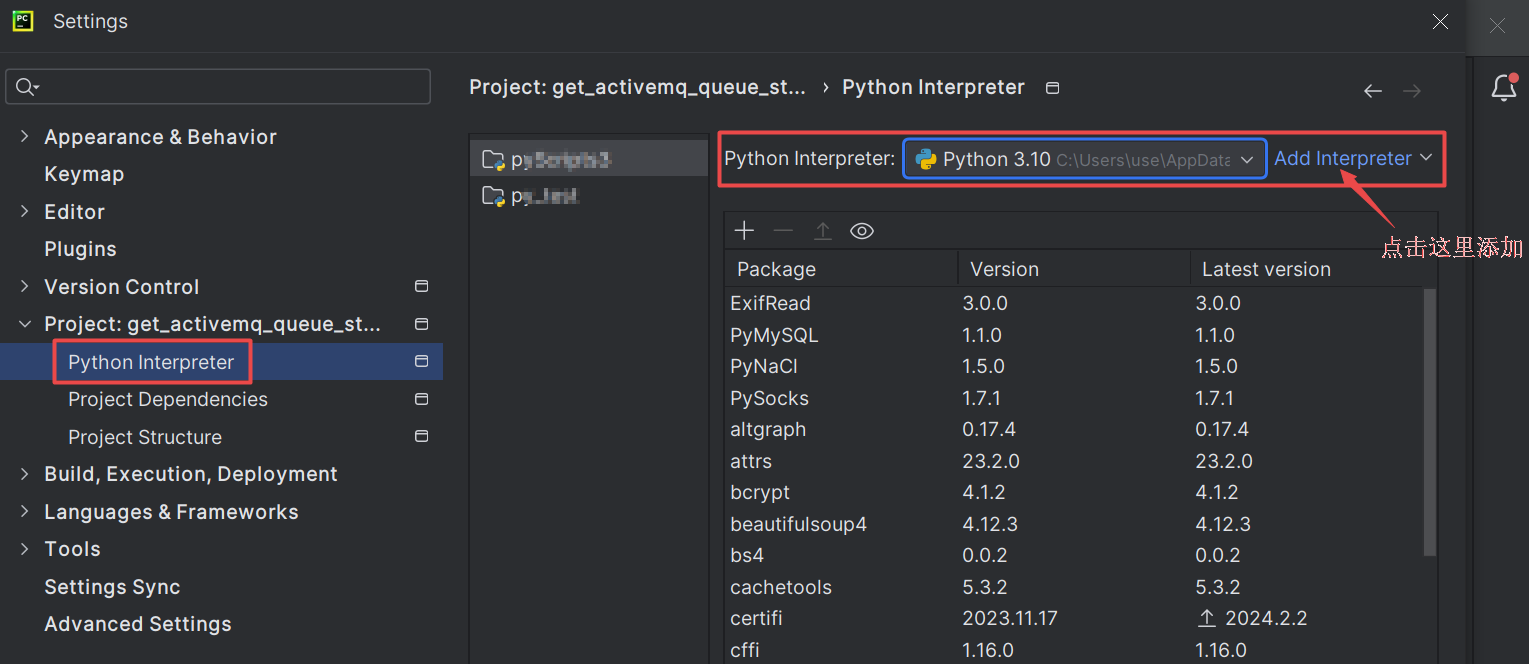
或点击右下角 进入设置
四、说说python虚拟环境
virtualenv提供了一套“隔离”的Python运行环境,更方便于提供多版本Python应用开发环境。
用上述pip即可安装好Python虚拟环境。pip3 install virtualenv。
注:几乎没用过,这里就提一下。不过现在生产环境中多用Docker,因此虚拟环境在生产环境也不怎么使用。
五、pycharm解释器种类
Virtualenv EnvironmentConda EnvironmentSystem InterpreterPipenv EnvironmentPoetry Environment
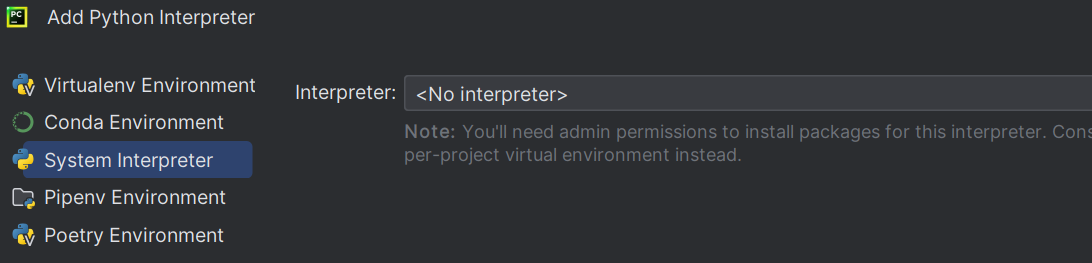
六、知识拓展
6.1 Conda 是什么
Conda 是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。外文名:Conda;适用:Linux,OS X 和Windows;代表工具:Python 环境管理工具;
6.2 Anaconda 是什么
Anaconda是一个程序,附加的有python程序。
简单来说,Anaconda是包管理器和环境管理器。Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的。在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
Anaconda是一个用于科学计算的 Python发行版,它支持多种操作系统,包括 Linux、Mac和 Windows。Anaconda是一个Python编程语言的开发环境,它包含了众多科学计算和数据分析库,如NumPy、SciPy、Pandas、Matplotlib等。Anaconda使得Python的科学计算和数据分析变得更加方便和易于使用。
anaconda指的是一个开源的python发行版本,是一个安装、管理python相关包的软件,自带了python、jupyter notebook、spyder、conda等工具,非常有用。
6.3 pip 和 conda 的区别
包管理器:pip conda
虚拟环境管理器: conda virtualenv 和 pyenv
pip 是在python 环境中管理python包的工具
conda 是在conda环境中管理python包和其它包(例如C语言包)的工具,以及虚拟环境管理器,它类似于另外两个很流行的环境管理器,即 virtualenv 和 pyenv。
二者是不同的东西,不可以混用,它们安装的东西不在一个地方。