网络系统设计师是干什么的深圳网站的优化公司哪家好
1、微服务概念
微服务是一种非常流行的架构风格。
拒绝大型单体应用,基于业务边界进行服务微化拆分,各个服务独立部署运行。
- 每个服务运行在自己的单个进程
- 使用轻量级机制通信
- 可以使用不同的编程语言编写以及不同的数据存储技术
2、集群&分布式&节点
2.1 集群概念
集群是个物理形态,只要是一堆机器就可以叫集群。它们是不是一起协作干活,还是各自干各自的,这个谁也不知道。
2.2 分布式概念
分布式是个工作方式,分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像是单个相关系统,比如京东商城。
- 分布式是指将不同的业务分布在不同的地方
- 集群是指将几台服务器集中在一起,实现同一业务
通俗来说,可以将分布式和集群比作一群人在搬家的例子:
- 集群:一群人在一起搬家,他们可以共同完成同一个任务。如果其中一个人出了问题,其他人可以继续完成这个任务,所以整个任务可以更快地完成。同样,如果需要搬到更大的房子,只需增加更多的人即可。这里每个人扮演的角色是相同的,即每个人都是负责搬家的工人。
- 分布式:一群人分成几组,分别搬不同的东西,例如有一组负责家具,一组负责装饰品等。每个组都有自己的领导,并且他们必须同步完成各自的任务,以便整个搬家过程能够成功。同样,如果需要搬到更大的房子,可能需要增加更多的组,而不是增加更多的人。这里每个人扮演的角色是不同的,即每个人都有自己的职责和任务。
因此,集群通常用于处理同一任务的场景,例如 Web 服务器集群,而分布式则更适用于处理不同任务的场景,例如大规模的数据处理。
总之,尽管分布式和集群都可以提高系统的可靠性、扩展性和性能,但它们之间有一些细微的区别,需要根据具体的情况来选择最合适的技术。
总结:
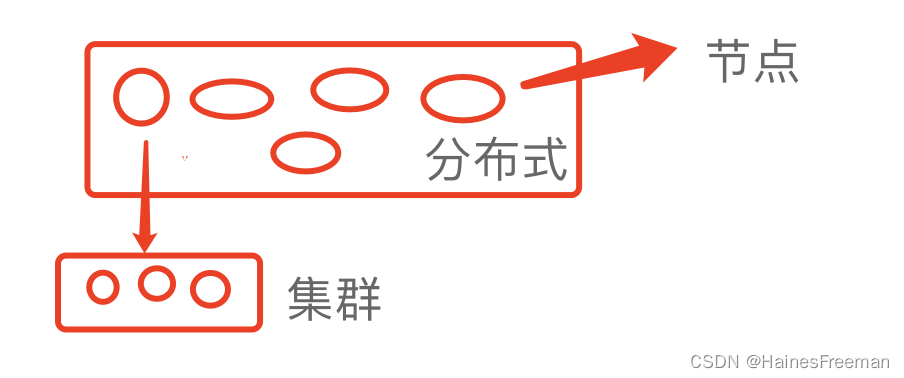
节点:集群中的一个服务器
- 分布式中的每一个节点都可以做集群
- 而集群不一定就是分布式的
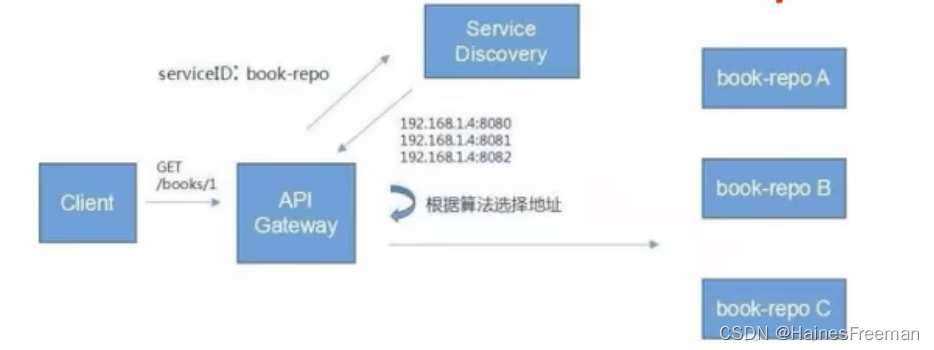
3、远程调用
在分布式系统中,各个服务可能分布在不同的主机,但是服务之间不可避免地要需要互相调用,我们称为远程调用。
比如 订单模块 去 商品模块 查询商品信息。
4、负载均衡
分布式系统中,A服务需要调用B服务(如订单模块调用商品模块),B服务在多台机器中都存在,A服务调用任意一台B服务都可以完成功能。
- 负载均衡的思想:不让某个机器太忙,也不要让某个机器太闲。
- 负载均衡的好处:提高系统的健壮性和性能。
常用的负载均衡算法:
- 轮询
- 按顺序往后依次选择,直到选择最后一个,依次循环。
- 最小连接
- 优先选择连接数最小的机器,也就是压力最小的后端服务器(在会话较长的情况下,优先考虑这种情况)

5、服务注册/发现&注册中心
A服务调用B服务,A服务并不知道B服务在哪几台机器上面,哪些是正常的,哪些服务已经下线,解决这些问题可以引入服务注册。避免调用不可用的服务。

6、配置中心
每个服务最终都有大量的配置,并且每个服务都可能部署在多个机器上面,我们经常需要变更某个服务的配置,设想一下假如我们有几百台服务器,难道要进入每一台进行改动配置并重新部署吗?显然不合理。所以就有了配置中心的存在了。
配置中心用于集中管理微服务的配置信息,一处配置,改动都会改。

7、服务熔断&服务降级
在微服务架构中,微服务之间通过网络进行通信,存在相互依赖,当1台服务器不可用,有可能造成雪崩效应,要避免这种情况,必须要有容错机制保护服务。

- 服务熔断
设置服务超时,当调用的服务达到某个阀值,我们可以开启断路保护机制,后来的服务不再调用这个服务,而是本地直接返回默认的数据。
- 服务降级
当系统处于资源紧张时期,我们可以让非核心业务降级运行,降级:某些服务不处理,或则简单处理(返回异常,返回null,调用Mock数据)
8、API网关
APIGateway可以理解成生活中的安检系统。
在微服务架构中,API Gateway作为整体架构的重要组件,它抽象了微服务中都需要的公共功能,同时提供了:
- 客户端的负载均衡
- 服务自动熔断
- 灰度发布
- 统一认证
- 限流流控
- 日志统计
等功能。帮我们解决了很多API管理难题。