做旅游网站的意义农业网站平台建设方案
本文属于HTML/CSS专栏文章,适合WEB前端开发入门学习,详细介绍HTML/CSS如果使用,如果对你有所帮助请一键三连支持,对博主系列文章感兴趣点击下方专栏了解详细。
- 博客主页:Duck Bro 博客主页
- 系列专栏:HTML/CSS专栏
- 关注博主,后期持续更新系列文章
- 如果有错误感谢大家批评指出,一定及时修改
- 感谢大家点赞👍收藏⭐评论✍
【HTML专栏1】语法规范、基础结构标签
本文关键字:语法规范、基本结构标签
文章目录
- 【HTML专栏1】语法规范、基础结构标签
- 一、HTML语法规范
- 1. 基本语法概述
- 2. 标签结构关系
- 二、基础结构标签
- 1. 第一个HTML网页
- 2. 结构标签(骨架标签)
- 3. 基本结构组成(总结)
一、HTML语法规范
1. 基本语法概述
HTML是一种标记语言,用于定义网页结构和内容。以下是HTML的基本语法:
-
HTML文档以
<!DOCTYPE html>声明开头,告诉浏览器使用哪个HTML版本。 -
HTML文档由
<html>标签包围,所有的元素都在这个标签之间。 -
一个HTML元素通常由一个起始标签
<html>、内容和一个结束标签</html>组成。起始标签和结束标签通常成对出现,内容则位于它们之间。 -
HTML元素可以有属性,这些属性提供了元素更多的信息,包括样式、链接和其他特性。
-
HTML元素可以嵌套,即一个元素可以包含另一个元素。
-
HTML标记对大小写不敏感,但建议使用小写标记。
-
有些特殊的标签必须是单个标签(极少情况),例如
<br />,称为单标签。
示例:
<!DOCTYPE html>
<html>
<head><title>My Title</title>
</head>
<body><h1>My Heading</h1><p>My paragraph.</p>
</body>
</html>
在这个例子中,声明了HTML版本,<html>开始了文档,<head>包含页面的标题信息和其他元数据,则包含页面的主要内容。<h1>和<p>是两个基本的HTML元素,分别用于定义标题和段落。
2. 标签结构关系
双标签关系可以分为两类:包含关系和并列关系
包含关系:
<title>被包含在<head>标签中,称为包含关系
<head><title>My Title</title>
</head>

并列关系:
<head>和<body>并列,称为并列关系
<head></head>
<body></body>

二、基础结构标签
1. 第一个HTML网页
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>第一个HTML网页</title>
</head>
<body></body>
</html>
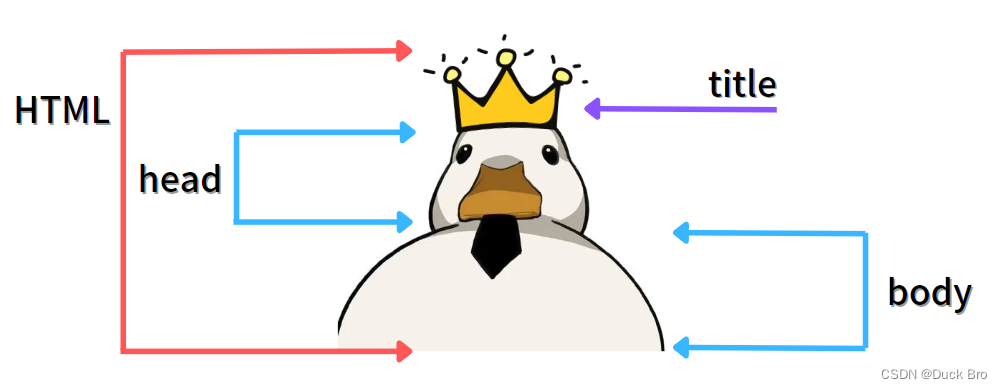
2. 结构标签(骨架标签)
| 标签名 | 定义 | 说明 |
|---|---|---|
<html> </html> | HTML标签 | 页面中最大的标签,我们 称为 根标签 |
<head> </head> | 文档的头部 | 注意在head标签中我们必须要设置的标签是title |
<title> </title> | 文档的标题 | 让页面拥有一个属于自己的网页标题 |
<body> </body> | 文档的主体 | 元素包含文档的所有内容,页面内容 基本都是放到body里面的 |
HTML 文档的的后缀名必须是 .html 或 .htm ,浏览器的作用是读取 HTML 文档,并以网页的形式显示出它们。
3. 基本结构组成(总结)