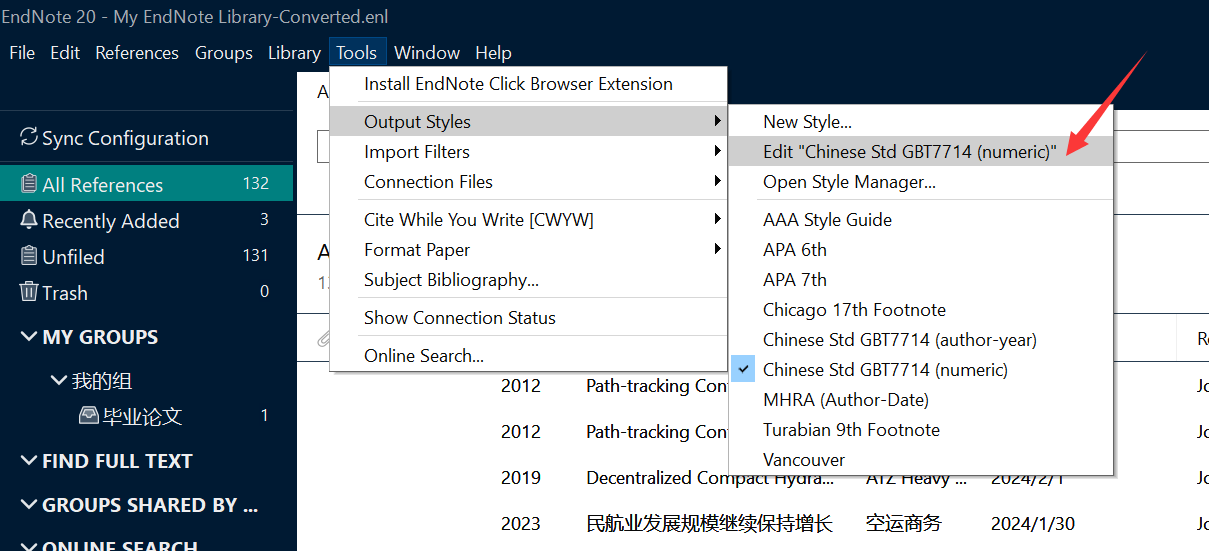
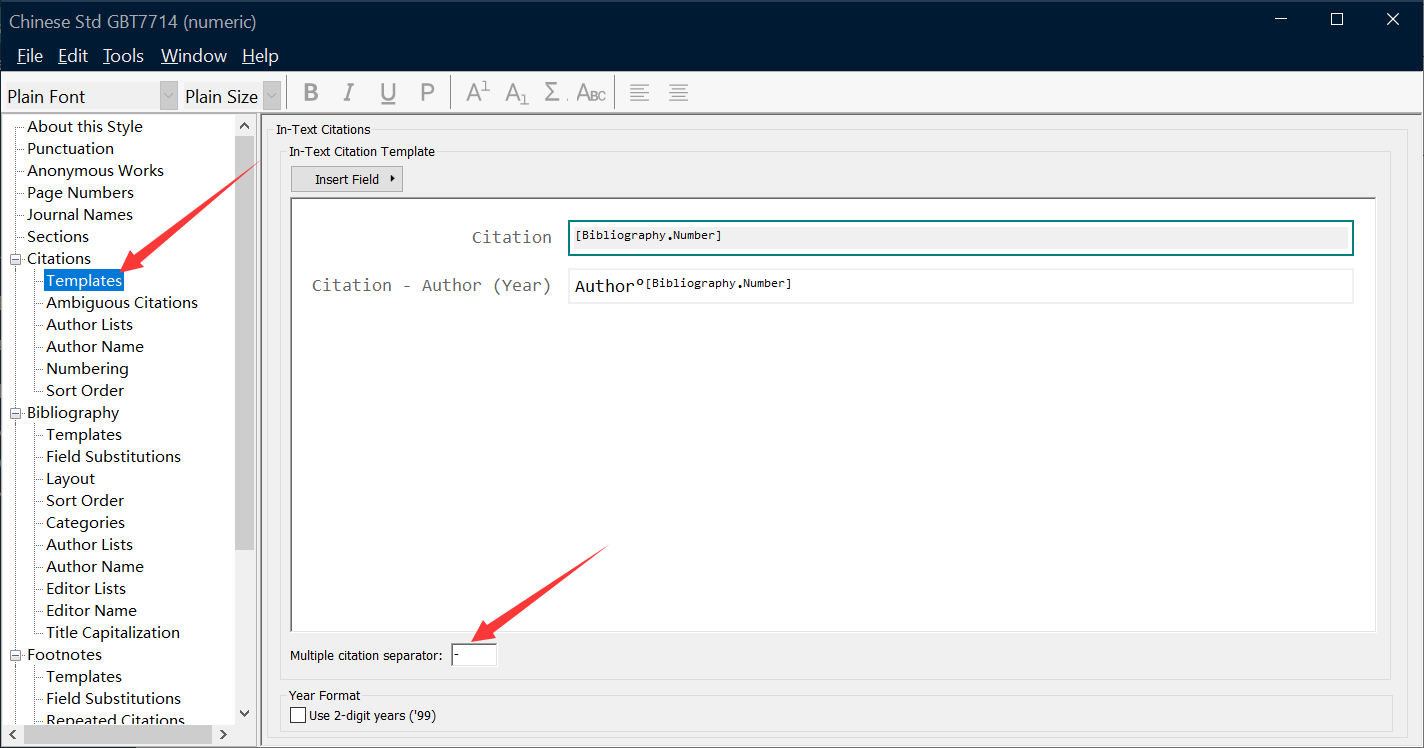
当前位置: 首页 > news >正文 网上祭奠类网站怎么做培训手机软件开发 news 2026/1/9 10:13:27 网上祭奠类网站怎么做,培训手机软件开发,域名备案需要有网站吗,免费个人简历表 查看全文 http://www.huolong8.cn/news/317/ 相关文章: